In previous articles such as The Road to Transformer Upgrade: 3. From Performer to Linear Attention and Why are current LLMs all Decoder-only architectures?, we explored the Attention mechanism from the perspective of the “rank” of the Attention matrix. We once judged that the key reason why linear Attention is inferior to standard Attention is precisely the “low-rank bottleneck.” However, while this explanation might hold for bidirectional Encoder models, it is difficult to apply to unidirectional Decoder models. This is because the upper triangular part of the Decoder’s Attention matrix is masked, leaving a lower triangular matrix that is necessarily full rank. Since it is full rank, the low-rank bottleneck problem seemingly no longer exists.
Therefore, the “low-rank bottleneck” cannot fully explain the performance deficiencies of linear Attention. In this article, the author attempts to seek an explanation from another perspective. Simply put, compared to standard Attention, linear Attention finds it harder to “focus attention,” making it difficult to accurately locate key tokens. This is likely the primary reason for its slightly inferior performance.
Degree of Sparsity
In the article Looking at the Scale Operation of Attention from Entropy Invariance, we examined the Attention mechanism from the perspective of “focusing attention.” At that time, we used information entropy as a measure of the “degree of concentration”; lower entropy indicates that Attention is more likely to be concentrated on a specific token.
However, for general Attention mechanisms, the Attention matrix may be non-normalized. For example, the GAU module introduced in FLASH: Possibly the Most Interesting Efficient Transformer Design Recently, and the l_2 normalized Attention introduced in A Theoretical Defect and Countermeasure for Relative Position Encoding Transformers. Even from the more general perspective of Non-Local Neural Networks, the Attention matrix is not necessarily non-negative. These non-normalized or even non-positive Attention matrices are naturally unsuitable for information entropy, as information entropy is defined for probability distributions.
To this end, we consider the l_1/l_2 form of the sparsity metric introduced in How to Measure the Sparsity of Data?: S(x) = \frac{\mathbb{E}[|x|]}{\sqrt{\mathbb{E}[x^2]}} This metric is similar to information entropy; a smaller S(x) means the corresponding random vector is sparser. Greater sparsity implies a higher likelihood of a “winner-takes-all” scenario, which corresponds to a one-hot distribution in probability. Unlike information entropy, it is applicable to general random variables or vectors.
Simplified Form
For the attention mechanism, let \boldsymbol{a} = (a_1, a_2, \cdots, a_n), where a_j \propto f(\boldsymbol{q}\cdot\boldsymbol{k}_j). Then: S(\boldsymbol{a}) = \frac{\mathbb{E}_{\boldsymbol{k}}[|f(\boldsymbol{q}\cdot\boldsymbol{k})|]}{\sqrt{\mathbb{E}_{\boldsymbol{k}}[f^2(\boldsymbol{q}\cdot\boldsymbol{k})]}} Next, we consider the limit as n \to \infty. Assuming \boldsymbol{k} \sim \mathcal{N}(\boldsymbol{\mu}, \sigma^2\boldsymbol{I}), we can set \boldsymbol{k} = \boldsymbol{\mu} + \sigma \boldsymbol{\varepsilon}, where \boldsymbol{\varepsilon} \sim \mathcal{N}(\boldsymbol{0}, \boldsymbol{I}). Thus: S(\boldsymbol{a}) = \frac{\mathbb{E}_{\boldsymbol{\varepsilon}}[|f(\boldsymbol{q}\cdot\boldsymbol{\mu} + \sigma\boldsymbol{q}\cdot\boldsymbol{\varepsilon})|]}{\sqrt{\mathbb{E}_{\boldsymbol{\varepsilon}}[f^2(\boldsymbol{q}\cdot\boldsymbol{\mu} + \sigma\boldsymbol{q}\cdot\boldsymbol{\varepsilon})]}} Note that the distribution \mathcal{N}(\boldsymbol{0}, \boldsymbol{I}) followed by \boldsymbol{\varepsilon} is isotropic. Following the same simplification logic as derived in Distribution of the Angle Between Two Random Vectors in n-dimensional Space, due to isotropy, the mathematical expectation related to \boldsymbol{q}\cdot\boldsymbol{\varepsilon} depends only on the magnitude of \boldsymbol{q} and not its direction. Thus, we can simplify \boldsymbol{q} to (\Vert\boldsymbol{q}\Vert, 0, 0, \cdots, 0), and the expectation over \boldsymbol{\varepsilon} simplifies to: S(\boldsymbol{a}) = \frac{\mathbb{E}_{\varepsilon}[|f(\boldsymbol{q}\cdot\boldsymbol{\mu} + \sigma\Vert\boldsymbol{q}\Vert\varepsilon)|]}{\sqrt{\mathbb{E}_{\varepsilon}[f^2(\boldsymbol{q}\cdot\boldsymbol{\mu} + \sigma\Vert\boldsymbol{q}\Vert\varepsilon)]}} where \varepsilon \sim \mathcal{N}(0, 1) is a random scalar.
Two Examples
We can now calculate and compare some common functions f. Currently, the most commonly used Attention mechanism is f = \exp. In this case, calculating the expectation is just a standard one-dimensional Gaussian integral, which easily yields: S(\boldsymbol{a}) = \exp\left(-\frac{1}{2}\sigma^2\Vert\boldsymbol{q}\Vert^2\right) As \sigma \to \infty or \Vert\boldsymbol{q}\Vert \to \infty, S(\boldsymbol{a}) \to 0. This means that, theoretically, standard Attention can indeed “focus attention” with arbitrary sparsity. At the same time, this tells us how to make attention more concentrated: increase the magnitude of \boldsymbol{q}, or increase the variance between different \boldsymbol{k}’s—in other words, widen the gap between \boldsymbol{k}’s.
Another example is the author’s preferred GAU (Gated Attention Unit). When it was first proposed, it used f = \text{relu}^2 (though the author reverted to Softmax when using it personally; see FLASH: Possibly the Most Interesting Efficient Transformer Design Recently and I Heard Attention and Softmax Go Better Together...). In this case, the integral is not as simple as f = \exp, but it can be calculated directly using Mathematica. The result is: S(\boldsymbol{a}) =\frac{e^{-\frac{\beta ^2}{2 \gamma ^2}} \left(\sqrt{2} \beta \gamma +\sqrt{\pi } e^{\frac{\beta ^2}{2 \gamma ^2}} \left(\beta ^2+\gamma ^2\right) \left(\text{erf}\left(\frac{\beta }{\sqrt{2} \gamma }\right)+1\right)\right)}{\sqrt[4]{\pi } \sqrt{2 \sqrt{2} \beta \gamma e^{-\frac{\beta ^2}{2 \gamma ^2}} \left(\beta ^2+5 \gamma ^2\right)+2 \sqrt{\pi } \left(\beta ^4+6 \beta ^2 \gamma ^2+3 \gamma ^4\right) \left(\text{erf}\left(\frac{\beta }{\sqrt{2} \gamma }\right)+1\right)}} where \beta = \boldsymbol{q}\cdot\boldsymbol{\mu} and \gamma = \sigma\Vert\boldsymbol{q}\Vert. The formula is daunting, but it doesn’t matter; we can just plot it:
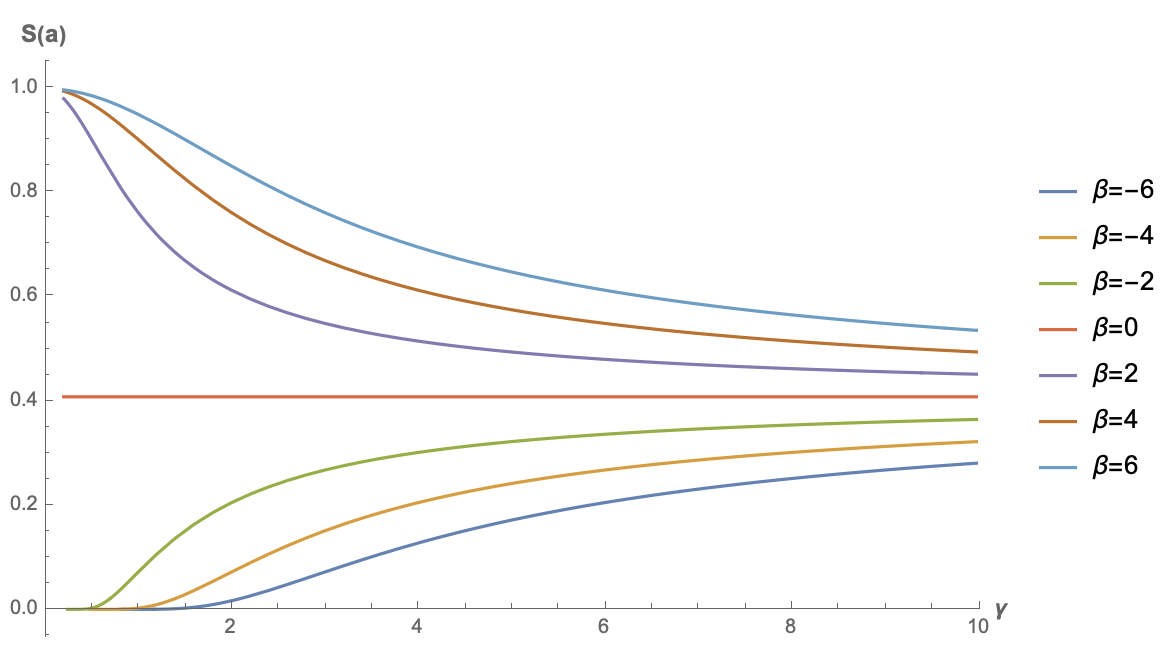
As can be seen, only when \beta < 0 does the sparsity of the original GAU have a chance to approach 0. This is also intuitive: when the bias term is less than 0, there is a greater chance for the result of \text{relu} to be 0, thereby achieving sparsity. This result also indicates that, unlike standard attention where f = \exp, the bias term of \boldsymbol{k} might have a positive impact on GAU with f = \text{relu}^2.
Minimal Linear
Next, let’s look at the simplest example: no f, or equivalently, f = \text{identical}. This case corresponds to the simplest form of linear Attention. Similarly, using Mathematica to calculate: S(\boldsymbol{a}) =\frac{\sqrt{\frac{2}{\pi }} \gamma e^{-\frac{\beta ^2}{2 \gamma ^2}}+\beta \text{erf}\left(\frac{\beta }{\sqrt{2} \gamma }\right)}{\sqrt{\beta ^2+\gamma ^2}} Below are the function plots for several different values of \beta:
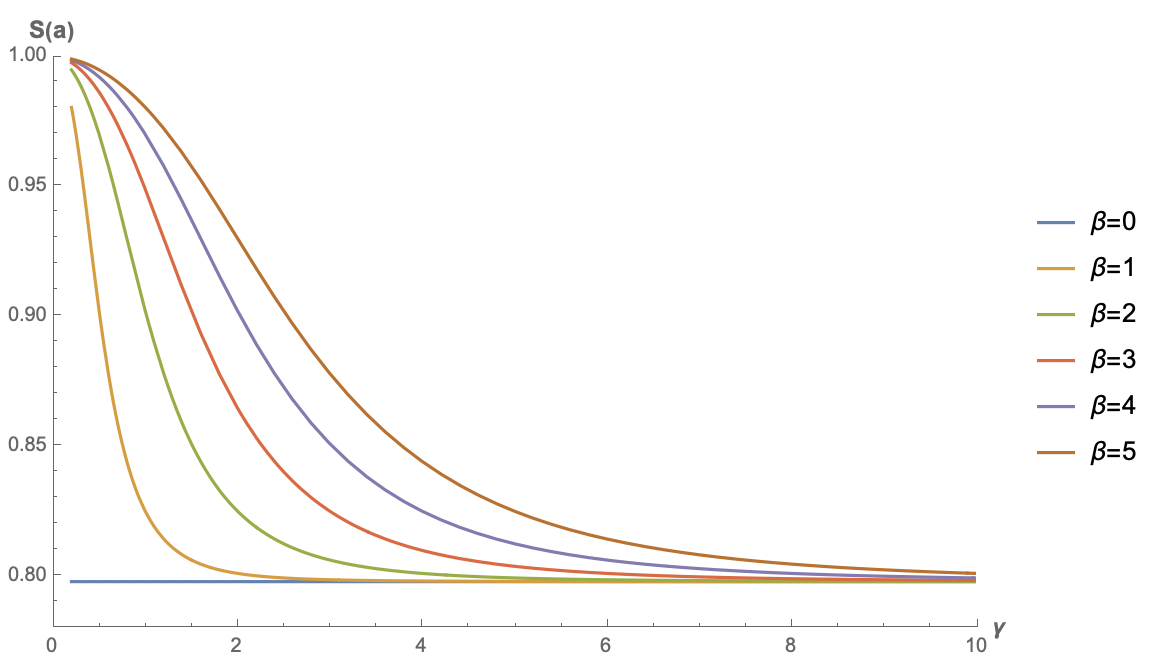
Note that S(\boldsymbol{a}) is an even function with respect to \beta (the reader might try to prove this). Therefore, the plot for \beta < 0 is the same as the plot for its negative counterpart. Thus, the figure only shows results for \beta \geq 0. From the figure, it is evident that the sparsity of linear Attention without any activation function cannot approach 0; instead, it has a relatively high lower bound. This means that when the input sequence is long enough, this type of linear Attention cannot “focus attention” on key positions.
General Linear
From Exploration of Linear Attention: Does Attention Must Have a Softmax?, we know that the general form of linear Attention is a_j \propto g(\boldsymbol{q})\cdot h(\boldsymbol{k}_j), where g, h are non-negative activation functions. Let \tilde{\boldsymbol{q}}=g(\boldsymbol{q}) and \tilde{\boldsymbol{k}}=h(\boldsymbol{k}). Then a_j\propto \tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{k}}, and we can write: S(\boldsymbol{a}) = \frac{\mathbb{E}_{\boldsymbol{\varepsilon}}\left[\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{k}}\right]}{\sqrt{\mathbb{E}_{\boldsymbol{\varepsilon}}\left[\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{k}}\tilde{\boldsymbol{k}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{q}}\right]}} = \frac{\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\mathbb{E}_{\boldsymbol{\varepsilon}}\left[\tilde{\boldsymbol{k}}\right]}{\sqrt{\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\mathbb{E}_{\boldsymbol{\varepsilon}}\left[\tilde{\boldsymbol{k}}\tilde{\boldsymbol{k}}^{\scriptscriptstyle\top}\right]\tilde{\boldsymbol{q}}}} = \frac{\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{\mu}}}{\sqrt{\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\left[\tilde{\boldsymbol{\mu}}\tilde{\boldsymbol{\mu}}^{\scriptscriptstyle\top} + \tilde{\boldsymbol{\Sigma}}\right]\tilde{\boldsymbol{q}}}} = \frac{1}{\sqrt{1 + \frac{\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{\Sigma}}\tilde{\boldsymbol{q}}}{(\tilde{\boldsymbol{q}}^{\scriptscriptstyle\top}\tilde{\boldsymbol{\mu}})^2}}} This is the general result for non-negative linear Attention. No approximations have been made yet; \tilde{\boldsymbol{\mu}} and \tilde{\boldsymbol{\Sigma}} are the mean vector and covariance matrix of the \tilde{\boldsymbol{k}} sequence, respectively.
From this result, it can be seen that non-negative linear Attention can also be arbitrarily sparse (i.e., S(\boldsymbol{a})\to 0), provided the mean tends to 0 or the covariance tends to \infty. In other words, the signal-to-noise ratio of the \tilde{\boldsymbol{k}} sequence should be as small as possible. However, the \tilde{\boldsymbol{k}} sequence is a sequence of non-negative vectors. A non-negative sequence with a very low signal-to-noise ratio implies that most elements in the sequence are similar. Consequently, such a sequence can express limited information. This also means that linear Attention can usually only represent the importance of absolute positions (e.g., a column in the Attention matrix being all 1s) and cannot well-express the importance of relative positions. This is essentially a manifestation of the low-rank bottleneck of linear Attention.
To more intuitively perceive the variation of S(\boldsymbol{a}), let’s assume the simplest case: each component of \tilde{\boldsymbol{k}} is independent and identically distributed (i.i.d.). In this case, the mean vector simplifies to \tilde{\mu}\boldsymbol{1} and the covariance matrix simplifies to \tilde{\sigma}^2\boldsymbol{I}. Then the formula for S(\boldsymbol{a}) can be further simplified to: S(\boldsymbol{a}) = \frac{1}{\sqrt{1 + \left(\frac{\tilde{\sigma}}{\tilde{\mu}}\frac{\Vert\tilde{\boldsymbol{q}}\Vert_2}{\Vert\tilde{\boldsymbol{q}}\Vert_1}\right)^2}} This result is much more direct to observe. To make linear attention sparse, one direction is to increase \frac{\tilde{\sigma}}{\tilde{\mu}}, i.e., lower the signal-to-noise ratio of the \tilde{\boldsymbol{k}} sequence. The other direction is to increase \frac{\Vert\boldsymbol{q}\Vert_2}{\Vert\boldsymbol{q}\Vert_1}. The maximum value of this factor is \sqrt{d}, where d is the dimension of \boldsymbol{q} and \boldsymbol{k}. Therefore, increasing it means increasing d. Increasing d implies raising the upper bound of the rank of the attention matrix. This aligns with the conclusion from the low-rank bottleneck perspective: only by increasing d can the deficiencies of linear Attention be fundamentally alleviated.
Specifically, as analyzed in The Road to Transformer Upgrade: 5. Linear Attention as Infinite Dimensions, standard Attention can also be understood as a type of infinite-dimensional linear Attention. This means that, theoretically, only by increasing d to infinity can the gap between the two be completely closed.
Linear Decay
Finally, let’s look at the linear RNN model series introduced in Google’s New Work Attempts to “Revive” RNN: Can RNN Shine Again?. Their characteristic is an explicit recursion, which can be viewed as a simple Attention: \boldsymbol{a} = (a_1, a_2, \cdots, a_{n-1}, a_n) = (\lambda^{n-1}, \lambda^{n-2}, \cdots, \lambda, 1) where \lambda \in (0, 1]. We can calculate: S(\boldsymbol{a}) = \sqrt{\frac{1 - \lambda^n}{n(1-\lambda)}\frac{1+\lambda}{1+\lambda^n}} < \sqrt{\frac{1}{n}\frac{1+\lambda}{(1-\lambda)(1+\lambda^n)}} When \lambda < 1, as long as n \to \infty, S(\boldsymbol{a}) \to 0. Therefore, for linear RNN models with explicit decay, sparsity is not an issue. Their problem is that they can only express a fixed attention that decays as the relative distance increases, thus failing to adaptively focus on contexts that are sufficiently far away.
Summary
This article proposes the idea of examining the potential of different Attention mechanisms through the degree of sparsity of the Attention matrix. It concludes that quadratic Attention mechanisms have the potential to achieve arbitrarily sparse Attention matrices, while linear Attention does not easily achieve such sparsity, or can only achieve sparsity related to absolute positions. This may be one of the reasons for the limitations of linear Attention’s capabilities.
Reprinted from: https://kexue.fm/archives/9889