In the history of generative diffusion models, DDIM and Song Yang’s Diffusion SDE from the same period are considered milestones. This is because they established a close connection between diffusion models and the mathematical fields of Stochastic Differential Equations (SDE) and Ordinary Differential Equations (ODE). This allows us to utilize various existing mathematical tools from SDE and ODE theory to analyze, solve, and extend diffusion models. For instance, a large number of subsequent acceleration techniques for sampling are based on this foundation. It can be said that this opened up a completely new perspective on generative diffusion models.
In this article, we focus on ODEs. In previous posts of this series, such as (6), (12), (14), (15), and (17), we have derived the connection between ODEs and diffusion models. This article provides a brief introduction to sampling acceleration for diffusion ODEs and focuses on a novel acceleration scheme called “AMED,” which cleverly utilizes the idea of the “Mean Value Theorem.”
Euler Method
As mentioned earlier, we have already derived the connection between diffusion models and ODEs in several articles. Therefore, we will not repeat the derivation here but directly define the sampling of a diffusion ODE as solving the following ODE: \frac{d\boldsymbol{x}_t}{dt} = \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) \label{eq:dm-ode} where t \in [0, T], the initial condition is \boldsymbol{x}_T, and the result to be returned is \boldsymbol{x}_0. In principle, we do not care about the intermediate values \boldsymbol{x}_t for t \in (0, T); we only need the final \boldsymbol{x}_0. For numerical solution, we need to select nodes 0 = t_0 < t_1 < t_2 < \cdots < t_N = T. A common choice is: t_n = \left(t_1^{1 / \rho} + \frac{n-1}{N-1}\left(t_N^{1 / \rho} - t_1^{1 / \rho}\right)\right)^\rho where \rho > 0. This form comes from “Elucidating the Design Space of Diffusion-Based Generative Models” (EDM). AMED also adopts this scheme. Personally, I believe the choice of nodes is not a critical factor, so we will not delve into it here.
The simplest solver is the “Euler Method,” which uses a finite difference approximation: \left.\frac{d\boldsymbol{x}_t}{dt}\right|_{t=t_{n+1}} \approx \frac{\boldsymbol{x}_{t_{n+1}} - \boldsymbol{x}_{t_n}}{t_{n+1} - t_n} From this, we obtain: \boldsymbol{x}_{t_n} \approx \boldsymbol{x}_{t_{n+1}} - \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1})(t_{n+1} - t_n) This is also commonly referred to as the DDIM method, as DDIM was the first to notice that its sampling process corresponds to the Euler method for an ODE, subsequently deriving the corresponding ODE.
Higher-Order Methods
From the perspective of numerical solutions, the Euler method is a first-order approximation. Its characteristics are simplicity and speed, but its disadvantage is poor accuracy, meaning the step size cannot be too small. This implies that relying solely on the Euler method is unlikely to significantly reduce the number of sampling steps while maintaining sampling quality. Consequently, subsequent work on sampling acceleration has applied higher-order methods.
For example, intuitively, the difference \frac{\boldsymbol{x}_{t_{n+1}} - \boldsymbol{x}_{t_n}}{t_{n+1} - t_n} should be closer to the derivative at the midpoint rather than the derivative at the boundary. Therefore, replacing the right side with the average of the derivatives at t_n and t_{n+1} should yield higher accuracy: \frac{\boldsymbol{x}_{t_{n+1}} - \boldsymbol{x}_{t_n}}{t_{n+1} - t_n} \approx \frac{1}{2}\left[\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_n}, t_n) + \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1})\right] \label{eq:heun-0} From this, we get: \boldsymbol{x}_{t_n} \approx \boldsymbol{x}_{t_{n+1}} - \frac{1}{2}\left[\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_n}, t_n) + \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1})\right](t_{n+1} - t_n) However, \boldsymbol{x}_{t_n} appears on the right side, and our goal is to calculate \boldsymbol{x}_{t_n}. Thus, this equation cannot be used directly for iteration. To resolve this, we use the Euler method to “predict” \boldsymbol{x}_{t_n} and then substitute it into the equation: \begin{aligned} \tilde{\boldsymbol{x}}_{t_n} &= \boldsymbol{x}_{t_{n+1}} - \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1})(t_{n+1} - t_n) \\ \boldsymbol{x}_{t_n} &\approx \boldsymbol{x}_{t_{n+1}} - \frac{1}{2}\left[\boldsymbol{v}_{\boldsymbol{\theta}}(\tilde{\boldsymbol{x}}_{t_n}, t_n) + \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1})\right](t_{n+1} - t_n) \end{aligned} \label{eq:heun} This is the “Heun’s method” used in EDM, which is a second-order method. Each iteration requires calculating \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) twice, but the accuracy is significantly improved. Therefore, the number of iterations can be reduced, and the total computational cost is lowered.
There are many other variants of second-order methods. For instance, we could replace the right side of Eq. [eq:heun-0] with the function value at the midpoint t = (t_n + t_{n+1})/2, yielding: \boldsymbol{x}_{t_n} \approx \boldsymbol{x}_{t_{n+1}} - \boldsymbol{v}_{\boldsymbol{\theta}}\left(\boldsymbol{x}_{(t_n+t_{n+1})/2}, \frac{t_n+t_{n+1}}{2}\right)(t_{n+1} - t_n) The midpoint can also be determined in different ways. Besides the arithmetic mean (t_n + t_{n+1})/2, one could consider the geometric mean: \boldsymbol{x}_{t_n} \approx \boldsymbol{x}_{t_{n+1}} - \boldsymbol{v}_{\boldsymbol{\theta}}\left(\boldsymbol{x}_{\sqrt{t_n t_{n+1}}}, \sqrt{t_n t_{n+1}}\right)(t_{n+1} - t_n) \label{eq:dpm-solver-2} In fact, Eq. [eq:dpm-solver-2] is a special case of DPM-Solver-2.
In addition to second-order methods, there are many higher-order methods for solving ODEs, such as “Runge-Kutta methods” and “Linear Multistep methods.” However, whether they are second-order or higher-order, while they can accelerate diffusion ODE sampling to some extent, they are “general-purpose” methods. Because they are not customized for the specific background and form of diffusion models, it is difficult to reduce the number of sampling steps to the extreme (single digits).
Mean Value Theorem
Now, the protagonist of this article, AMED, enters the stage. Its paper, “Fast ODE-based Sampling for Diffusion Models in Around 5 Steps,” was just posted on Arxiv a couple of days ago. AMED does not simply aim to improve theoretical accuracy like traditional ODE solvers. Instead, it cleverly draws an analogy to the “Mean Value Theorem” and adds a very small distillation cost to customize a high-speed solver for diffusion ODEs.
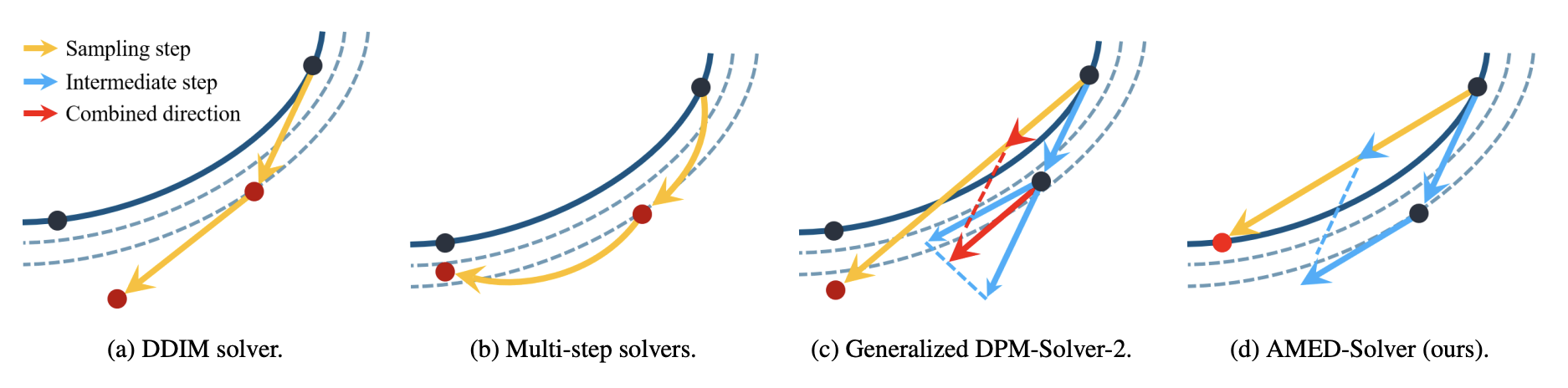
First, by integrating both sides of Eq. [eq:dm-ode], we can write an exact equality: \boldsymbol{x}_{t_{n+1}} - \boldsymbol{x}_{t_n} = \int_{t_n}^{t_{n+1}} \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) dt If \boldsymbol{v} were a one-dimensional scalar function, then by the “Mean Value Theorem for Integrals,” we would know there exists a point s_n \in (t_n, t_{n+1}) such that: \frac{1}{t_{n+1} - t_n} \int_{t_n}^{t_{n+1}} \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) dt = \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{s_n}, s_n) Unfortunately, the Mean Value Theorem does not hold for general vector-valued functions. However, if t_{n+1} - t_n is not too large and under certain assumptions, we can still write an analogy: \frac{1}{t_{n+1} - t_n} \int_{t_n}^{t_{n+1}} \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) dt \approx \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{s_n}, s_n) Thus, we obtain: \boldsymbol{x}_{t_n} \approx \boldsymbol{x}_{t_{n+1}} - \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{s_n}, s_n)(t_{n+1} - t_n) Of course, this is currently only a formal solution; how to obtain s_n and \boldsymbol{x}_{s_n} remains unresolved. For \boldsymbol{x}_{s_n}, we still use the Euler method for prediction: \tilde{\boldsymbol{x}}_{s_n} = \boldsymbol{x}_{t_{n+1}} - \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1})(t_{n+1} - s_n). For s_n, we use a small neural network to estimate it: s_n = g_{\boldsymbol{\phi}}(\boldsymbol{h}_{t_{n+1}}, t_{n+1}) where \boldsymbol{\phi} are the training parameters and \boldsymbol{h}_{t_{n+1}} are the intermediate features of the U-Net model \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_{n+1}}, t_{n+1}). Finally, to solve for the parameters \boldsymbol{\phi}, we adopt the idea of distillation. We pre-calculate high-precision trajectory point pairs (\boldsymbol{x}_{t_n}, \boldsymbol{x}_{t_{n+1}}) using a solver with more steps and then minimize the estimation error. This is the AMED-Solver (Approximate MEan-Direction Solver) described in the paper. It possesses the form of a conventional ODE solver but requires additional distillation costs. However, this distillation cost is almost negligible compared to other distillation acceleration methods, which is why I interpret it as a “customized” solver.
The word “customized” is crucial. Research on accelerating diffusion ODE sampling has a long history. With the contributions of many researchers, non-training solvers have likely come a very long way, but they still fail to reduce the number of sampling steps to the absolute minimum. Unless there is a further breakthrough in our theoretical understanding of diffusion models in the future, I do not believe non-training solvers have significant room for improvement. Therefore, the acceleration provided by AMED, which involves a small training cost, is both an “unconventional approach” and a “natural progression.”
Experimental Results
Before looking at the experimental results, let’s first understand a concept called “NFE,” which stands for “Number of Function Evaluations.” Simply put, it is the number of times the model \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) is executed, which is directly linked to the computational load. For example, the NFE per step for a first-order method is 1, because \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) only needs to be executed once. For a second-order method, the NFE per step is 2. Since the computational cost of g_{\boldsymbol{\phi}} in AMED-Solver is very small and can be ignored, the NFE per step for AMED-Solver is also considered to be 2. To achieve a fair comparison, the total NFE throughout the sampling process must be kept constant when comparing the effects of different solvers.
The basic experimental results are shown in Table 2 of the original paper:
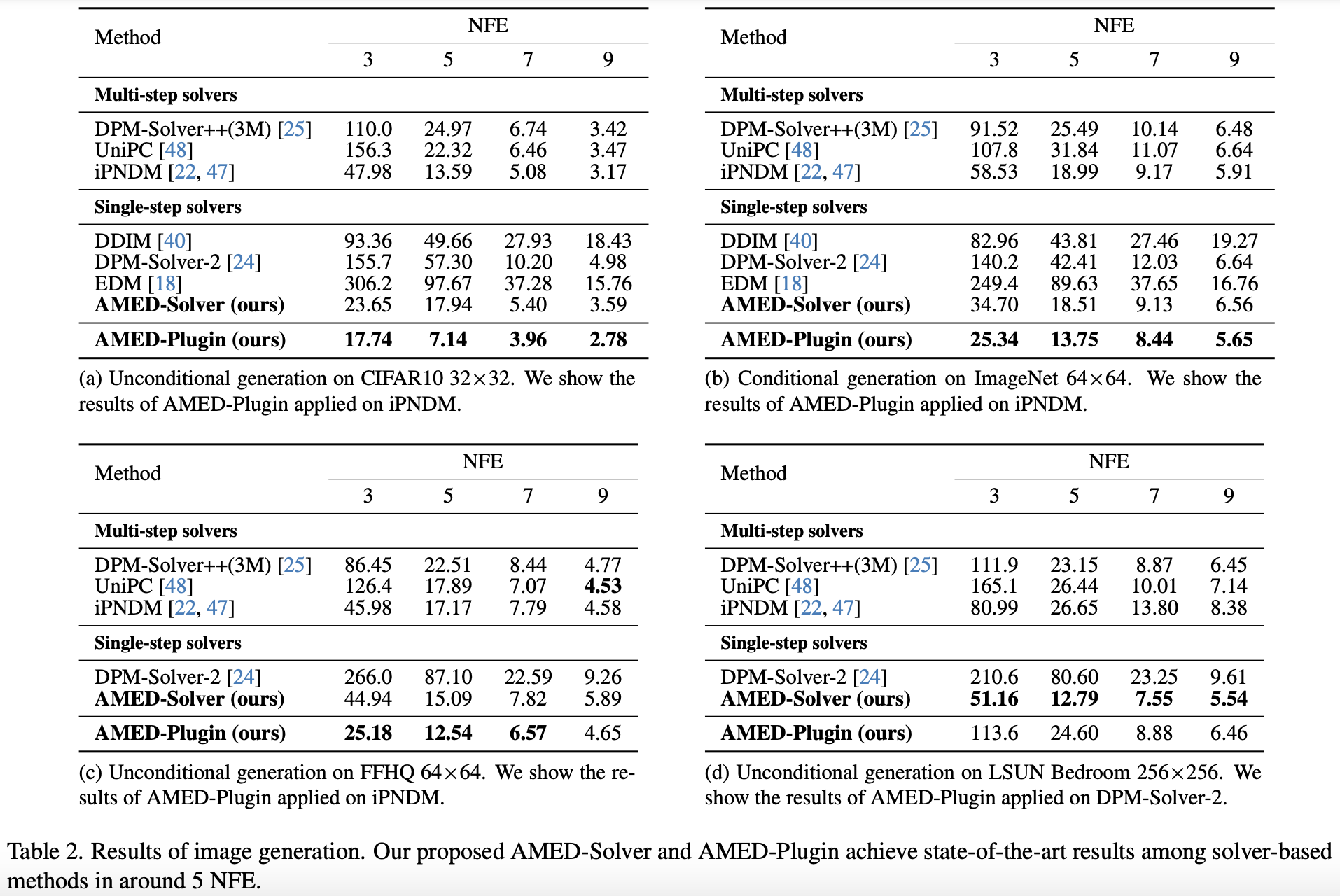
There are several points in this table worth noting. First, when the NFE does not exceed 5, the second-order DPM-Solver and EDM perform worse than the first-order DDIM. This is because the error of a solver depends not only on the order but also on the step size t_{n+1} - t_n. The relationship is roughly \mathcal{O}((t_{n+1} - t_n)^m), where m is the “order.” When the total NFE is small, higher-order methods are forced to take larger step sizes, so their actual accuracy is worse, leading to poor performance. Second, the AMED-Solver, which is also a second-order method, achieves comprehensive SOTA results at small NFEs, fully demonstrating the importance of “customization.” Third, the “AMED-Plugin” mentioned here is a usage proposed in the original paper where the idea of AMED is used as a “plugin” for other ODE solvers. The details are more complex, but it achieves even better results.
Some readers might wonder: since second-order methods require 2 NFEs per iteration, why do odd NFEs appear in the table? This is because the authors used a technique called “AFS (Analytical First Step)” to reduce the NFE by 1. This technique comes from “Genie: Higher-order denoising diffusion solvers.” Specifically, in the context of diffusion models, it is found that \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_N}, t_N) is very close to \boldsymbol{x}_{t_N} (different diffusion models may behave differently, but the core idea is that the first step can be solved analytically). Thus, in the first step of sampling, \boldsymbol{x}_{t_N} is used directly to replace \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_{t_N}, t_N), saving one NFE. Tables 8, 9, and 10 in the paper’s appendix provide a more detailed evaluation of the impact of AFS on performance, which interested readers can analyze themselves.
Finally, since AMED used a distillation method to train g_{\boldsymbol{\phi}}, some readers might want to know the performance difference between it and other distillation acceleration schemes. Unfortunately, the paper does not provide a direct comparison. I inquired with the author via email, and the author stated that the distillation cost of AMED is extremely low. CIFAR10 requires less than 20 minutes of training on a single A100, and 256 \times 256 images only require a few hours on four A100s. In contrast, other distillation acceleration approaches require days or even dozens of days. Therefore, the author views AMED as a solver-related work rather than a distillation-related work. However, the author also mentioned that they would try to include comparisons with distillation work in the future if possible.
Assumption Analysis
Earlier, when discussing the extension of the Mean Value Theorem to vector functions, we mentioned “under certain assumptions.” What are these assumptions? And do they actually hold?
It is easy to provide counterexamples showing that the Integral Mean Value Theorem does not hold universally even for two-dimensional functions. In other words, the theorem only strictly holds for one-dimensional functions. This implies that if the Mean Value Theorem holds for a high-dimensional function, the spatial trajectory described by that function must be a straight line. That is, all points \boldsymbol{x}_{t_0}, \boldsymbol{x}_{t_1}, \dots, \boldsymbol{x}_{t_N} in the sampling process must form a straight line. This assumption is naturally very strong and almost impossible to hold in reality. However, it also tells us that for the Mean Value Theorem to hold as much as possible in high-dimensional space, the sampling trajectory should remain in as low-dimensional a subspace as possible.
To verify this, the authors increased the number of sampling steps to obtain a relatively accurate sampling trajectory and then performed Principal Component Analysis (PCA) on the trajectory. The results are shown below:
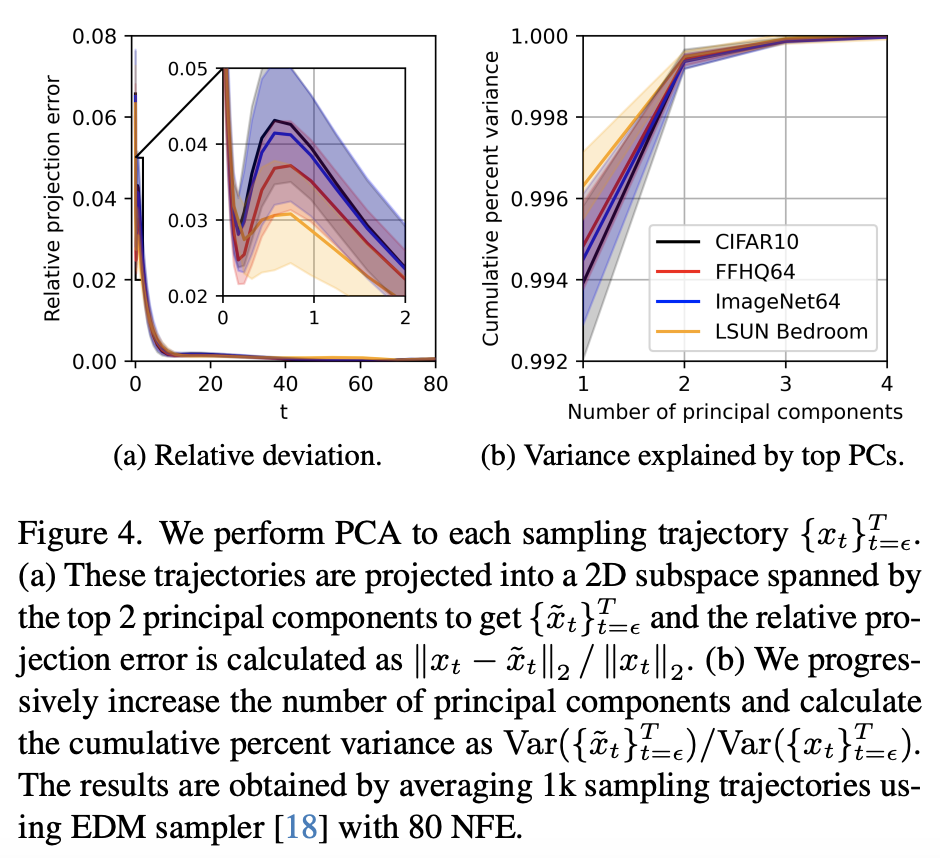
The PCA results show that retaining only the top-1 principal component preserves most of the trajectory’s accuracy. If the first two principal components are retained, the remaining error is almost negligible. This tells us that the sampling trajectories are almost entirely concentrated on a two-dimensional sub-plane, and are even very close to a straight line within that plane. Thus, when t_{n+1} - t_n is not particularly large, the Integral Mean Value Theorem in the high-dimensional space of the diffusion model holds approximately.
This result might be surprising, but it can be explained in hindsight. In Part 15 and Part 17 of this series, we introduced the general steps for constructing a diffusion ODE by first specifying a “pseudo-trajectory” from \boldsymbol{x}_T to \boldsymbol{x}_0. In practical applications, the “pseudo-trajectories” we construct are linear interpolations between \boldsymbol{x}_T and \boldsymbol{x}_0 (they might be non-linear with respect to t, but they are linear with respect to \boldsymbol{x}_T and \boldsymbol{x}_0). Consequently, the constructed “pseudo-trajectories” are straight lines, which further encourages the real diffusion trajectory to be a straight line. This explains the PCA results.
Conclusion
This article briefly reviewed sampling acceleration methods for diffusion ODEs and focused on a novel acceleration scheme called “AMED” released just a few days ago. This solver constructs an iterative format by analogy with the Integral Mean Value Theorem, improving the performance of the solver at low NFEs with minimal distillation cost.
When reposting, please include the original address of this article: https://kexue.fm/archives/9881
For more detailed reposting matters, please refer to: “Scientific Space FAQ”