As the mainstream model architecture for Large Language Models (LLMs), the Transformer performs excellently across various tasks. In most cases, the main criticism of the Transformer is its quadratic complexity rather than its effectiveness—except for a benchmark called Long Range Arena (hereafter referred to as LRA). For a long time, LRA has been the "home turf" for linear RNN-like models. Compared to them, the Transformer shows a significant gap on this benchmark, leading some to wonder if this is an inherent flaw of the Transformer architecture.
However, a recent paper titled "Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors" has filled this "missing link." The paper points out that the lack of pre-training is the primary reason for the Transformer’s poor performance on LRA. While all architectures can gain some improvement through pre-training, the boost for the Transformer is significantly more pronounced.
Old Background
Long Range Arena (LRA) is a benchmark for long-sequence modeling, proposed in the paper "Long Range Arena: A Benchmark for Efficient Transformers". As the title suggests, LRA was constructed to test various efficient versions of the Transformer. It contains multiple types of data with sequence lengths ranging from 1k to 16k. Many previous works on Efficient Transformers have been tested on LRA. Although there is some controversy regarding its representativeness, LRA remains a classic benchmark for testing the long-sequence capabilities of Efficient Transformers.
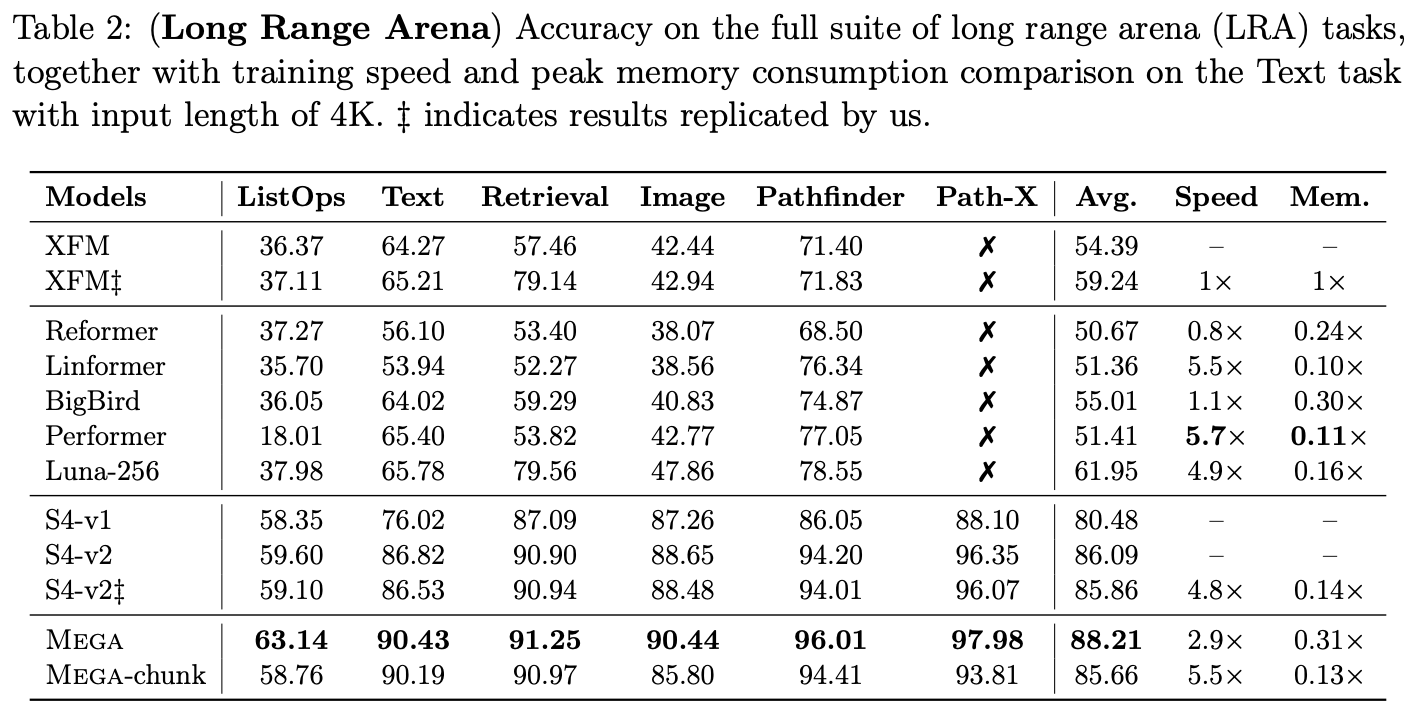
It might surprise some readers that the standard Transformer (XFM) does not perform well on this benchmark, lagging significantly behind a series of linear RNN-like models, such as the classic SSMs (S4, S4D, S5) or the LRU we introduced previously. Even the former SOTA model, MEGA, needed to be equipped with a linear RNN module (referred to as EMA in the paper) on top of GAU. In short, previous model rankings on LRA strongly signaled that "Attention is optional, but RNN is essential."
(Note: The full LRA leaderboard can be viewed at https://paperswithcode.com/sota/long-range-modeling-on-lra.)
New Conclusion
Clearly, the emergence of "Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors" has shattered this impression. It points out that pre-training on the training set can greatly narrow the gap between the two and further proposes the view that "without pre-training, there is no fair comparison."
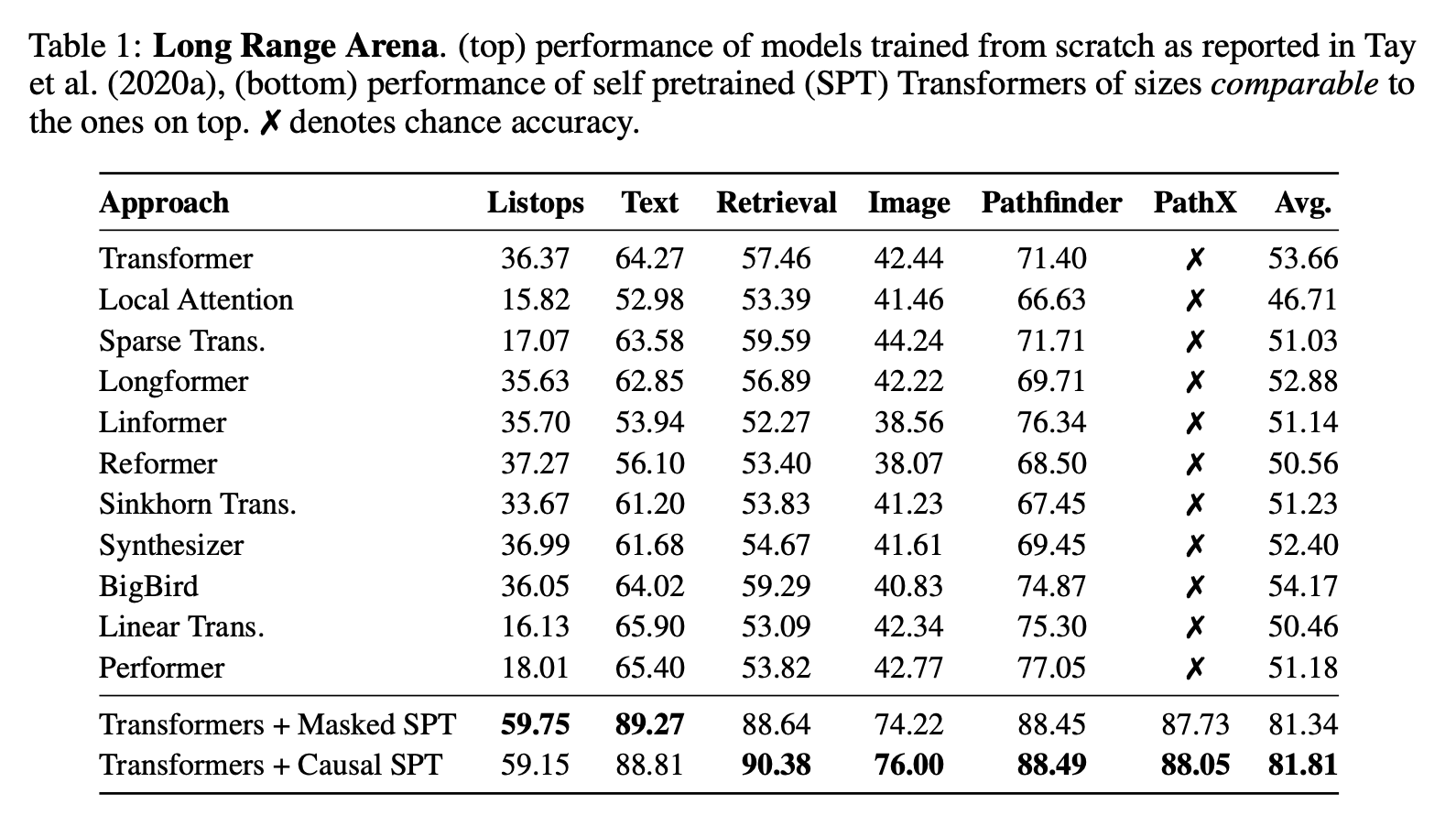
The pre-training approach is simple: one can choose either MLM (Masked Language Modeling) or GPT (Generative Pre-trained Transformer) as the task, and the dataset remains the original training set. In this way, no additional knowledge sources are introduced except for increased computational consumption, making the comparison fair. In fact, both Transformers and RNNs achieve significant improvements after pre-training, but the improvement for the Transformer is much more substantial:


In hindsight, the paper’s conclusion does not seem surprising and even feels "obviously true," but previously, it seems no one thought in this direction (or perhaps they thought of it but didn’t consider it critical?). Therefore, the authors’ realization and demonstration of the importance of pre-training on LRA is still very much worth commending.
The importance of pre-training actually highlights the significance of Inductive Bias on LRA. To make sequences long enough, LRA uses very fine-grained tokenization. For example, text tasks use characters as tokens, and image tasks use pixels as tokens, flattening 2D images directly into 1D sequences. Obviously, these tasks require both long-range dependencies and have clear locality. Linear RNNs happen to fit these characteristics very well. In contrast, the Transformer has less obvious Inductive Bias; it requires additional positional encoding to have positional information, and even with it, there is no significant locality. Therefore, it needs pre-training more to adapt to data characteristics or, in other words, to supplement Inductive Bias through pre-training.
Conclusion
This article has quickly shared a relatively new experimental conclusion: pre-training can effectively improve the performance of various models on LRA. In particular, after pre-training, the Transformer’s performance can essentially approach the SOTA tier. This breaks the long-standing impression I held that LRA must be supplemented with linear RNNs.