If large-scale pre-trained models are the “brilliant strategies” (Zhang Liang’s plans) of Natural Language Processing, then what is the corresponding “scaling ladder” (the counter-strategy)? In my opinion, it is the various techniques for efficiently fine-tuning these large models for specific tasks. In addition to directly fine-tuning all parameters, there are many parameter-efficient fine-tuning (PEFT) techniques such as Adapter and P-Tuning. These methods can achieve performance close to full-parameter fine-tuning by updating only a very small number of parameters. However, these techniques are usually only “parameter-efficient” and not necessarily “training-efficient.” This is because they still require backpropagation through the entire model to obtain gradients for the small subset of trainable parameters. Simply put, while the number of trainable parameters is significantly reduced, the training speed does not see a significant increase.
A recent paper titled “LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning” proposes a new training technique called “Ladder Side-Tuning (LST),” which claims to achieve both parameter efficiency and training efficiency. Is there really such an ideal “scaling ladder”? Let us explore it together.
Main Idea
The structure of the LST “ladder” can be clearly explained using Figure 2 from the original paper:
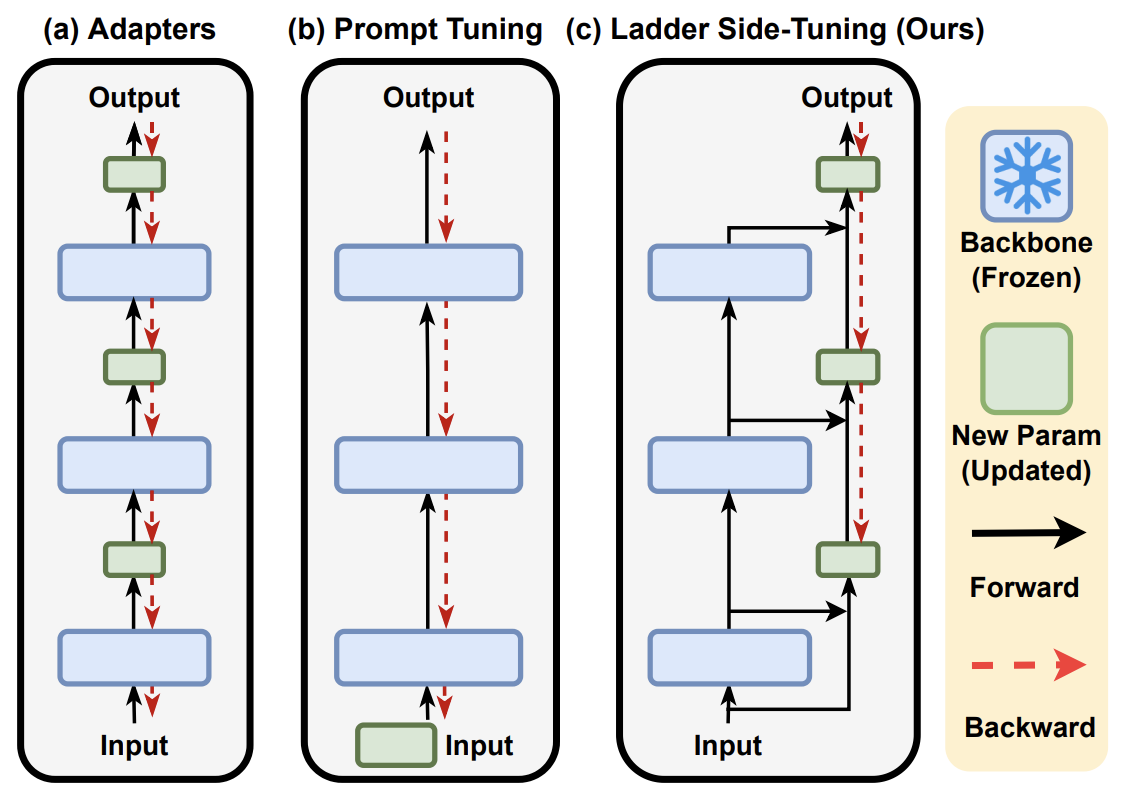
Backpropagation, which calculates model gradients, proceeds step-by-step from the output layer toward the input layer. Therefore, the depth/computational cost of backpropagation depends on the depth of the trainable parameters closest to the input layer; it is not necessarily tied to the total number of trainable parameters. For the Adapter, a small-scale layer is inserted after each original layer. Although the rest of the parameters are fixed and only the newly inserted layers are trainable, since there are new layers at every level, backpropagation must still propagate back to the input layer. For P-tuning, it essentially has a small number of trainable parameters in the Embedding layer. However, the Embedding layer is the input layer, so backpropagation must still traverse the entire model. Consequently, these two schemes do not significantly improve training efficiency.
As for LST, it builds a “side branch” (a ladder) on top of the original large model. The outputs of some layers of the large model are used as inputs for the side-branch model. All trainable parameters reside exclusively within the side-branch model. Since the large model only provides inputs (acting as a fixed feature extractor), the complexity of backpropagation depends on the scale of the side-branch model. There is no need to perform backpropagation through the original large model itself, which significantly improves training efficiency.
Experimental Results
The original paper conducted several experiments with LST across NLP and CV tasks. Below are the results of LST on the GLUE dataset:
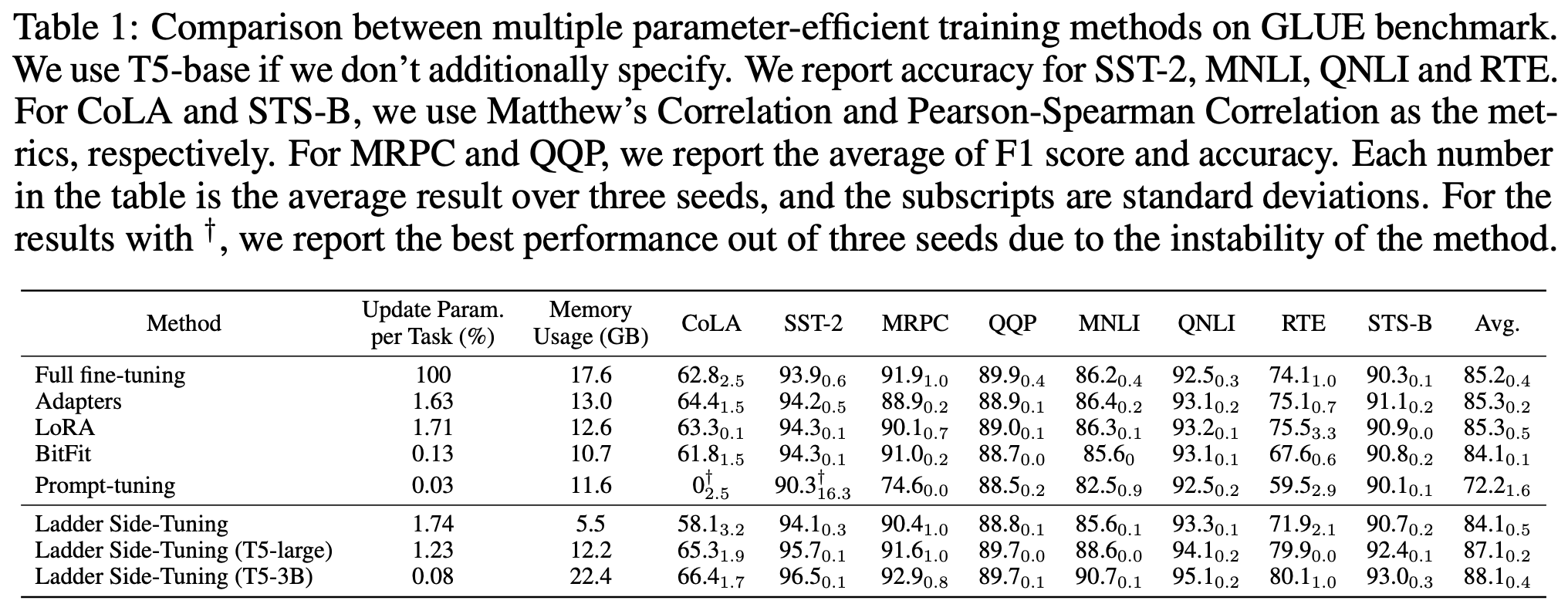
As we can see, LST indeed possesses the characteristics of being both parameter-efficient and training-efficient. It achieves good fine-tuning results with fewer trainable parameters and lower training costs. In particular, the experimental results in the last two rows demonstrate the possibility of fine-tuning large models using LST under limited training resources.
I also conducted a simple trial on the Chinese CLUE tasks. The reference code can be found here:
Note that in the original paper, the “ladder” is constructed using MLP layers similar to those in Adapters. In my implementation, I directly used a combination of “Attention + FFN” similar to a Transformer. The number of trainable parameters was controlled at approximately 1 million, which is about 1.2% of the base version or 0.4% of the large version. The ladder was initialized randomly. The final results on the validation set are as follows:
| iflytek | tnews | afqmc | cmnli | ocnli | wsc | csl | cmrc2018 | c3 | chid | cluener | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT base | 60.06 | 56.80 | 72.41 | 79.56 | 73.93 | 78.62 | 83.93 | 56.17 | 60.54 | 85.69 | 79.45 |
| RoBERTa base | 60.64 | 58.06 | 74.05 | 81.24 | 76.00 | 87.50 | 84.50 | 56.54 | 67.66 | 86.71 | 79.47 |
| RoBERTa base + LST | 59.29 | 56.82 | 70.37 | 76.27 | 71.02 | 68.09 | 82.63 | 42.50 | 56.97 | 69.35 | 78.30 |
| RoBERTa large + LST | 60.41 | 57.12 | 72.36 | 75.80 | 72.07 | 75.00 | 84.23 | 39.98 | 60.19 | 72.55 | 77.80 |
It can be observed that the experimental results are not as optimistic as the English experiments in the original paper (though I cannot rule out that my own implementation might not be optimal). However, the training efficiency indeed improved significantly (on average, it was about twice as fast). Throughout the experiments, my impression was that for conventional classification tasks of average difficulty, LST can achieve similar results. However, for more difficult tasks, such as reading comprehension, LST shows a very significant performance drop.
Of course, LST is likely not the only method with this issue. Most fine-tuning methods claiming parameter efficiency probably face similar challenges, as the experimental tasks for these methods are mostly GLUE, which consists of relatively simple classification tasks...
Further Reflections
With the benefit of hindsight, LST is not an incredibly sophisticated approach. Essentially, it fixes the pre-trained model and uses its output layer and some intermediate layer results as supplementary inputs to train a new small model. Once this is understood, many readers might already be formulating similar schemes in their minds. However, the true significance of LST lies in showing us that this approach is viable, providing a feasible reference scheme, and experimentally proving that it is an effective way to utilize large models.
Readers with similar research experience will notice that the initialization of the newly added “ladder” branch in LST is a problem. If it is completely randomly initialized, there may be training difficulties, and the results may be suboptimal. The original paper also mentions this and provides a scheme for intercepting weight matrices from the large model to serve as initializations for the small model’s matrices, thereby improving the final performance of LST. The details can be found in the paper. As for my own implementation, it was purely a simple verification of LST’s effectiveness, so I was lazy and did not implement this step.
Taking this a step further: since the initialization of the “ladder” branch in LST is a challenge, and LST is indeed an effective scheme for fine-tuning large models, could we perhaps reserve this “ladder” in advance when training new large models in the future? That is, we could directly include this “ladder” as part of the pre-trained model during large-scale pre-training. Later, during fine-tuning, we would only fine-tune the “ladder.” This would allow for efficient fine-tuning of large models without worrying about initialization issues.
In terms of form, I find LST quite similar to the method introduced in “BERT-of-Theseus: A Model Compression Method Based on Module Replacement.” However, the goal of the latter is model distillation, which still requires backpropagation through the large model. In contrast, the goal of LST is to improve training efficiency, which does not require backpropagation through the large model, although the large model is still needed for forward propagation during inference. One could say the two are somewhat complementary.
Summary
This article introduced Ladder Side-Tuning, a fine-tuning method for large models that is both parameter-efficient and training-efficient.
When reposting, please include the original address of this article: https://kexue.fm/archives/9138
For more detailed reposting matters, please refer to: "Scientific Space FAQ"