Just like “XXX is all you need,” many papers are titled “An Embarrassingly Simple XXX.” In my view, most of these papers are more about hype than substance. However, I recently read a paper that truly makes one exclaim, “This is embarrassingly simple!”
The title of the paper is “Finite Scalar Quantization: VQ-VAE Made Simple.” As the name suggests, this work aims to simplify VQ-VAE using FSQ (Finite Scalar Quantization). With the increasing popularity of generative models and multimodal LLMs, VQ-VAE and its subsequent works have gained significant importance as “Image Tokenizers.” However, the training of VQ-VAE itself has some issues. The FSQ paper claims that through a simpler “rounding” operation, the same goal can be achieved with the advantages of better performance, faster convergence, and more stable training.
Is FSQ really that magical? Let’s dive in and learn about it.
VQ
First, let’s understand “VQ.” VQ stands for “Vector Quantization,” which refers to a technique that maps infinite, continuous encoding vectors to a finite, discrete set of integers. If we apply VQ to the intermediate layer of an autoencoder, we can compress the input size while making the encoding result a sequence of discrete integers.
Assuming the reconstruction loss of the autoencoder is satisfactory, this integer sequence is an equivalent representation of the original image. All operations on the original image can be transformed into operations on the integer sequence. For example, if we want to train an image generation model, we only need to train an integer sequence generation model. Since this is equivalent to text generation, we can use it to train a GPT model, where the model and process are identical to those used for text. Once training is complete, we can sample an integer sequence from the GPT model and feed it into the decoder to obtain an image, thus completing the construction of an image generation model. Simply put, “VQ + Autoencoder” converts any input into an integer sequence consistent with text, unifying the input forms of different modalities as well as their processing and generation models.
An autoencoder with such VQ functionality is called a “VQ-VAE.”
AE
Four years ago, in the article “A Brief Introduction to VQ-VAE: Quantized Autoencoders,” we introduced VQ-VAE. Despite being named “VAE (Variational AutoEncoder),” it actually has little to do with VAEs. As mentioned in the previous section, it is simply an AE (AutoEncoder) with VQ functionality.
Since it is an AE, it has an encoder and a decoder. A standard AE looks like this: z = \text{encoder}(x),\quad \hat{x}=\text{decoder}(z),\quad \mathcal{L}=\Vert x - \hat{x}\Vert^2 VQ-VAE is slightly more complex: \begin{aligned} z =&\, \text{encoder}(x)\\[5pt] z_q =&\, z + \text{sg}[e_k - z],\quad k = \mathop{\text{argmin}}_{i\in\{1,2,\cdots,K\}} \Vert z - e_i\Vert\\ \hat{x} =&\, \text{decoder}(z_q)\\[5pt] \mathcal{L} =&\, \Vert x - \hat{x}\Vert^2 + \beta\Vert e_k - \text{sg}[z]\Vert^2 + \gamma\Vert z - \text{sg}[e_k]\Vert^2 \end{aligned}\label{eq:vqvae}
Let’s explain this step by step. First, the initial step is the same: input x into the encoder to output the encoding vector z. However, we do not feed z directly into the decoder. Instead, we maintain a codebook of encoding vectors \{e_1, e_2, \cdots, e_K\} and select the e_k that is closest to z to be sent to the decoder for reconstructing x. Since the codebook is finite, the actual encoding result can be understood as an integer (the index k of the e_k closest to z). This is the meaning of “VQ” in VQ-VAE.
In practice, to ensure reconstruction clarity, the encoder’s output may consist of multiple vectors, each undergoing the same quantization step to become an integer. Consequently, an image originally in continuous real space is encoded by VQ-VAE into a sequence of integers. This is similar to the role of a text Tokenizer, hence the term “Image Tokenizer.”
Gradient
However, because the \mathop{\text{argmin}} operation appears in the forward computation flow, gradients cannot propagate back to the encoder, meaning we cannot optimize the encoder. A common approach to address this is Gumbel Softmax, but its performance is often suboptimal. Therefore, the authors cleverly used the Straight-Through Estimator to design better gradients for VQ-VAE. One could say this is the most brilliant part of VQ-VAE; it tells us that while “Attention is all you need” is catchy, “Gradient” is truly “all we need”!
Specifically, VQ-VAE utilizes the stop_gradient function
(denoted as \text{sg} in the formulas),
which is available in almost all deep learning frameworks, to define
custom gradients. Any input passing through \text{sg} maintains the same output, but its
gradient is forced to zero. Thus, for z_q in equation [eq:vqvae], we
have: z_q = e_k,\quad \nabla z_q = \nabla
z\label{eq:sg} In this way, what is fed into the decoder is the
quantized e_k, but when the optimizer
calculates gradients, it uses z. Since
z is produced by the encoder, the
encoder can now be optimized. This operation is called the
“Straight-Through Estimator (STE),” a common technique for designing
gradients for non-differentiable modules in neural networks.
Since gradient-based optimizers remain the mainstream, directly designing gradients is often closer to the essence than designing losses—though it is usually more difficult and more admirable.
Loss
However, the story doesn’t end there. Two problems remain: 1. While the encoder now has gradients, the codebook e_1, e_2, \cdots, e_K does not; 2. Although \text{sg} allows us to define gradients arbitrarily, not just any gradient will successfully optimize the model. From [eq:sg], we can see that for it to be mathematically rigorous, the only solution is e_k = z. This tells us that if STE is reasonable, then e_k and z must at least be close. Therefore, for the sake of gradient rationality and to optimize the codebook, we add an auxiliary loss: \Vert e_k - z\Vert^2\label{eq:ez} This forces e_k and z to be close and allows e_k to have gradients—killing two birds with one stone! But upon closer reflection, there is a slight flaw: theoretically, the reconstruction loss of the encoder and decoder is already sufficient to optimize z, so the additional term should primarily optimize e_k and should not significantly affect z. To this end, we use the \text{sg} trick again. It is easy to prove that the gradient of equation [eq:ez] is equivalent to: \Vert e_k - \text{sg}[z]\Vert^2 + \Vert z - \text{sg}[e_k]\Vert^2 The first term stops the gradient for z, leaving only the gradient for e_k. The second term does the opposite. Currently, the two terms are summed with a 1:1 weight, meaning they influence each other equally. As we just said, this auxiliary loss should primarily optimize e_k rather than z. So, we introduce \beta > \gamma > 0 and change the auxiliary loss to: \beta\Vert e_k - \text{sg}[z]\Vert^2 + \gamma\Vert z - \text{sg}[e_k]\Vert^2\label{eq:ez2} Adding this to the reconstruction loss gives the total loss for VQ-VAE.
Additionally, there is another scheme for optimizing e_k: first, set \beta in equation [eq:ez2] to zero, so e_k has no gradient again. Then, we observe that the VQ operation in VQ-VAE is quite similar to K-Means clustering, where e_1, e_2, \cdots, e_K act as K cluster centers. Based on our knowledge of K-Means, a cluster center is the average of all vectors in that cluster. Thus, one optimization scheme for e_k is the moving average of z: e_k^{(t)} = \alpha e_k^{(t-1)} + (1-\alpha) z This is equivalent to using SGD to optimize the \Vert e_k - \text{sg}[z]\Vert^2 loss term (while other terms can use Adam, etc.). This scheme was used in VQ-VAE-2.
FSQ
Some readers might be wondering: isn’t the theme of this article FSQ? Isn’t the introduction to VQ-VAE a bit too long? In fact, because FSQ truly lives up to the description “embarrassingly simple,” it only takes a few lines to describe compared to VQ-VAE. If I didn’t write more about VQ-VAE, this blog post would be very short! Of course, detailing VQ-VAE also helps everyone appreciate the simplicity of FSQ more deeply.
To be precise, FSQ is just a replacement for the “VQ” part of VQ-VAE. Its discretization idea is extremely simple: “rounding.” First, assume we have a scalar t \in \mathbb{R}. We define: \text{FSQ}(t) \triangleq \text{Round}[(L-1)\sigma(t)] Here L \in \mathbb{N} is a hyperparameter, \sigma(x) = 1/(1+e^{-x}) is the sigmoid function (the original paper used \tanh, but I believe sigmoid is more scientific), and \text{Round} rounds to the nearest integer. It is easy to see that \text{FSQ}(t) \in \{0, 1, \cdots, L-1\}, meaning the FSQ operation restricts the output to L integers, thus achieving discretization. Of course, in most cases, one scalar is not enough. For z \in \mathbb{R}^d, FSQ can be performed on each dimension: \text{FSQ}(z) = \text{Round}[(L-1)\sigma(z)] \in \{0, 1, \cdots, L-1\}^d That is, a d-dimensional vector z is discretized into one of L^d integers. Note that the \text{Round} operation also has no gradient (or rather, the gradient is zero). However, after the preamble on VQ-VAE, some readers might have guessed what comes next: using the STE trick again: \text{FSQ}(z) = (L-1)\sigma(z) + \text{sg}\big[\text{Round}[(L-1)\sigma(z)] - (L-1)\sigma(z)\big] In other words, backpropagation uses the value before rounding, (L-1)\sigma(z), to calculate gradients. Since the values before and after \text{Round} are numerically close, FSQ does not require an additional loss to force approximation, nor is there an extra codebook to update. The simplicity of FSQ is evident!

Experiments
If VQ is understood as directly clustering encoding vectors into K different categories, then FSQ is about summarizing d attributes for the encoding vector, with each attribute divided into L levels, thus directly expressing L^d different integers. Of course, in the most general case, the number of levels for each attribute can be different, L_1, L_2, \cdots, L_d, resulting in L_1 L_2 \cdots L_d different combinations.
According to the original paper’s suggestion, L \geq 5 (the previous LFQ is equivalent to L=2). Therefore, to match the codebook size K of VQ-VAE, FSQ should have d = \log_L K. This means FSQ has a restriction on the dimension d of the encoding vector (usually a single digit), and it is typically much smaller than the encoding dimension of VQ-VAE (usually three digits). A direct consequence is that when the total number of codes K is small (and thus d is small), the performance of FSQ is usually inferior to VQ:
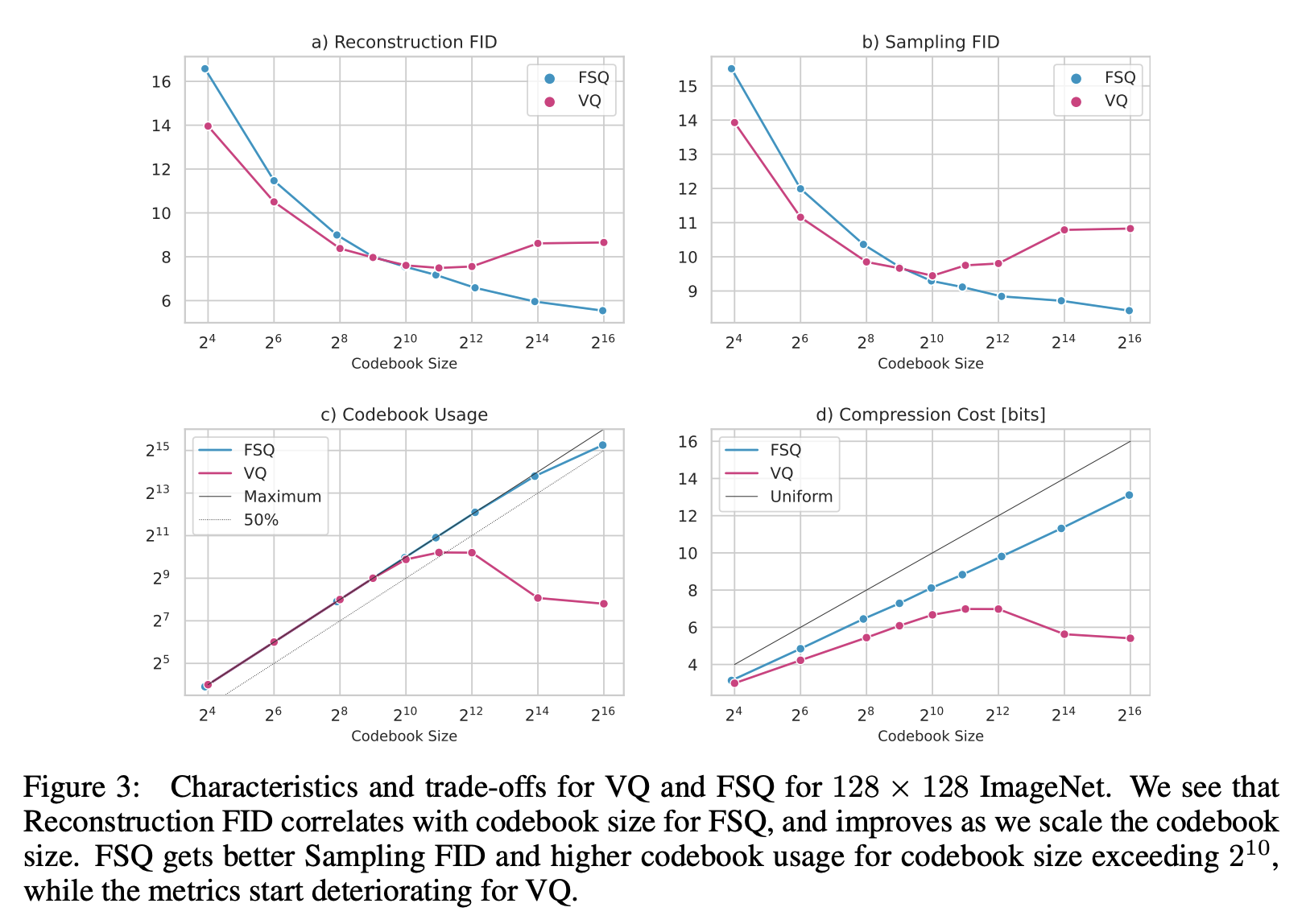
As seen from the figure, when the codebook size is around 1000, the performance of FSQ and VQ is similar. When the codebook size significantly exceeds 1000, FSQ has the advantage; conversely, when the codebook size is significantly smaller than 1000, VQ performs better. This aligns with my own experimental results. My reference code is available at:
Github: https://github.com/bojone/FSQ
Other experiments in the paper are standard tests demonstrating FSQ’s superiority across various tasks. Readers can refer to the original paper for details.
Thinking
Formally, assuming K = L^d, VQ is like a “classifier with L^d classes,” while FSQ is like “d scorers with L levels.” In terms of parameter count, geometric intuition, or expressive power, FSQ is actually inferior to VQ. But why does FSQ have the chance to achieve better results than VQ? I believe there are two reasons.
The first reason is that the encoder and decoder are very powerful. Although FSQ itself is weaker, the encoder and decoder are strong enough. Based on the universal approximation hypothesis of neural networks, the disadvantage of FSQ relative to VQ can be fully compensated for within the encoder and decoder. Under the K = L^d setting, the degree of discretization is the same for both, meaning the “information bottleneck” between the encoder and decoder is the same. Therefore, the inherent issues of FSQ become negligible.
The second reason is that VQ’s “teammate” (the gradient) is too weak. A classic problem with VQ is codebook collapse: as the codebook size increases, it is not fully utilized. Instead, due to fierce competition, the codebook vectors cluster together. A classic manifestation is that a codebook of size 5000 performs worse than one of size 500. Ultimately, this is caused by unreasonable gradients. Although VQ cleverly designed its gradients, for hard-assignment operations like \mathop{\text{argmin}}, gradient-based optimization suffers from the “winner-takes-all” problem, which is the root cause of collapse. FSQ’s \text{Round} operation does not involve assignment; it directly takes an approximate value. More broadly, K-Means, which is similar to VQ, often suffers from cluster center collapse. It is clear that optimizing \mathop{\text{argmin}} is a long-standing difficult problem. Therefore, rather than saying FSQ is too strong, it is more accurate to say VQ’s “teammate” is too weak.
From these two points of analysis, we can see that for FSQ to surpass VQ, not only must the codebook be large enough, but the encoder and decoder must also be sufficiently complex. This is not always satisfied. For example, in some scenarios, we want every layer’s output to be quantized. In such cases, the amortized complexity of the encoder and decoder might not be enough, and FSQ’s inherent deficiencies could become a performance bottleneck. Furthermore, the vector dimension after VQ does not change and can be any dimension, whereas the vector before FSQ must be projected to d = \log_L K dimensions. This is a severe dimensionality reduction. When we need to use the high-dimensional approximate vectors from before projection, it is difficult to recover them simply from the low-dimensional vectors after FSQ.
Therefore, if used purely as an “Image Tokenizer,” FSQ might already be able to replace VQ, but this does not mean VQ can be replaced by FSQ in every scenario.
Summary
This article introduced an extremely simple alternative to the “VQ” in VQ-VAE—FSQ (Finite Scalar Quantization). It directly discretizes continuous vectors through rounding and does not require additional auxiliary losses. Experimental results show that when the codebook is large enough, FSQ has an advantage over VQ.
When reposting, please include the original article address: https://kexue.fm/archives/9826
For more detailed reposting matters, please refer to: “Scientific Space FAQ”