When pre-training first emerged, it was a very common practice to reuse embedding weights at the output of language models. For instance, BERT, the first version of T5, and early versions of GPT all employed this technique. This was because when the model backbone was relatively small and the vocabulary was large, the number of parameters in the embedding layer was significant. Adding an independent weight matrix of the same size at the output would lead to a surge in memory consumption. However, as model parameter scales have increased, the proportion of the embedding layer has become relatively smaller. Furthermore, research such as "Rethinking embedding coupling in pre-trained language models" has suggested that sharing embeddings might have some negative impacts. Consequently, the practice of sharing embeddings has become increasingly rare.
This article aims to analyze the problems that may be encountered when sharing embedding weights and explore how to perform initialization and parameterization more effectively. Although sharing embeddings may seem "outdated," it remains an interesting research topic.
Weight Sharing
The practice of reusing embedding weights at the output of a language model is referred to in English as "Tied Embeddings" or "Coupled Embeddings." The core idea is that the size of the embedding matrix is identical to the projection matrix that transforms hidden states to logits at the output (differing only by a transpose). Since this parameter matrix is quite large, to avoid unnecessary waste, the same weights are shared, as shown in the figure below:
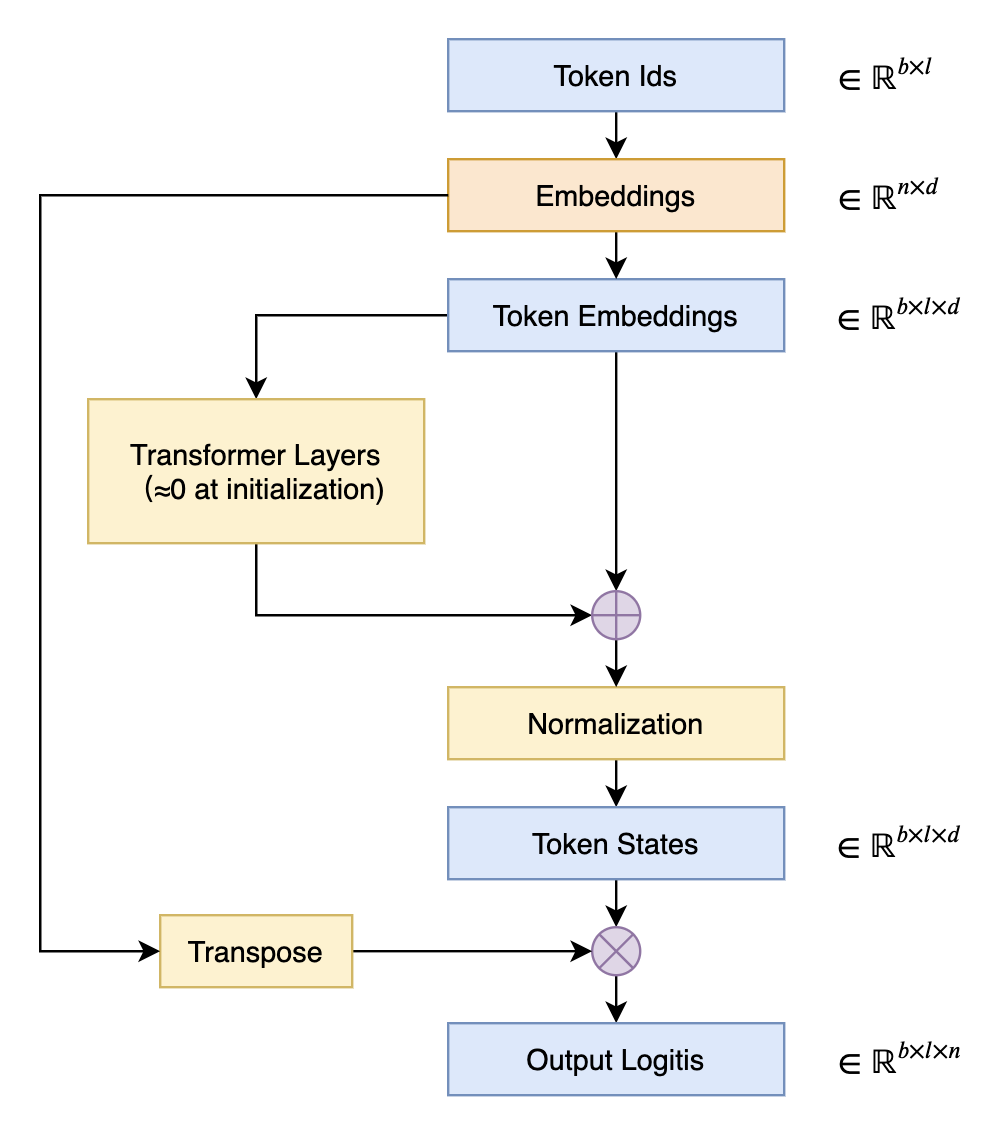
The most direct consequence of sharing embeddings is that it can lead to a very high initial loss during pre-training. This is because we typically use techniques like DeepNorm to reduce training difficulty, which initialize the residual branches of the model to be close to zero. In other words, at the initial stage, the model approximates an identity function, making the initial model equivalent to a 2-gram model with shared embeddings. Next, we will derive the reasons why such a 2-gram model has a high loss and analyze some solutions.
Preparation
Before formally beginning the derivation, we need to prepare some basic conclusions.
First, it must be clarified that we are primarily analyzing results at the initial stage. At this point, weights are sampled independently and identically distributed (i.i.d.) from a distribution with "mean 0 and variance \sigma^2." This allows us to estimate certain sums through expectations. For example, for a vector \boldsymbol{w}=(w_1,w_2,\cdots,w_d), we have: \mathbb{E}\left[\Vert \boldsymbol{w}\Vert^2\right] = \mathbb{E}\left[\sum_i w_i^2\right] = \sum_i \mathbb{E}\left[w_i^2\right] = d\sigma^2 \label{eq:norm} Therefore, we can take \Vert \boldsymbol{w}\Vert\approx \sqrt{d}\sigma. How large is the error? We can perceive it through its variance. To do this, we first find its second moment: \begin{aligned} \mathbb{E}\left[\Vert \boldsymbol{w}\Vert^4\right] =&\, \mathbb{E}\left[\left(\sum_i w_i^2\right)^2\right] = \mathbb{E}\left[\sum_i w_i^4 + \sum_{i,j|i\neq j} w_i^2 w_j^2\right] \\ =&\, \sum_i \mathbb{E}\left[w_i^4\right] + \sum_{i,j|i\neq j} \mathbb{E}\left[w_i^2\right] \mathbb{E}\left[w_j^2\right] \\ =&\, d\,\mathbb{E}\left[w^4\right] + d(d-1) \sigma^4 \\ \end{aligned} If the sampling distribution is a normal distribution, we can directly calculate \mathbb{E}\left[w^4\right]=3\sigma^4, so: \mathbb{V}ar\left[\Vert \boldsymbol{w}\Vert^2\right] = \mathbb{E}\left[\Vert \boldsymbol{w}\Vert^4\right] - \mathbb{E}\left[\Vert \boldsymbol{w}\Vert^2\right]^2 = 2d\sigma^4 This variance represents the degree of approximation for \Vert \boldsymbol{w}\Vert\approx \sqrt{d}\sigma. That is, the smaller the original sampling variance \sigma^2, the higher the degree of approximation. Specifically, a common sampling variance is 1/d (corresponding to \Vert \boldsymbol{w}\Vert\approx 1, i.e., a unit vector), then substituting into the above formula yields 2/d, meaning the higher the dimension, the higher the degree of approximation. Furthermore, if the sampling distribution is not normal, \mathbb{E}\left[w^4\right] can be recalculated, or the result for the normal distribution can simply be used as a reference; in any case, it is just an estimation.
If \boldsymbol{v}=(v_1,v_2,\cdots,v_d) is another i.i.d. vector, we can estimate the dot product using the same method, resulting in: \mathbb{E}\left[\boldsymbol{w}\cdot\boldsymbol{v}\right] = \mathbb{E}\left[\sum_i w_i v_i\right] = \sum_i \mathbb{E}\left[w_i\right] \mathbb{E}\left[v_i\right] = 0 \label{eq:dot} and \begin{aligned} \mathbb{E}\left[(\boldsymbol{w}\cdot\boldsymbol{v})^2\right] =&\, \mathbb{E}\left[\left(\sum_i w_i v_i\right)^2\right] = \mathbb{E}\left[\sum_i w_i^2 v_i^2 + \sum_{i,j|i\neq j} w_i v_i w_j v_j\right] \\ =&\, \sum_i \mathbb{E}\left[w_i^2\right]\mathbb{E}\left[v_i^2\right] + \sum_{i,j|i\neq j} \mathbb{E}\left[w_i\right]\mathbb{E}\left[v_i\right]\mathbb{E}\left[w_j\right]\mathbb{E}\left[v_j\right] \\ =&\, d \sigma^4 \\ \end{aligned} Similarly, taking \sigma^2=1/d, the variance is 1/d^3, and the higher the dimension, the higher the degree of approximation. These two results can be considered statistical versions of the conclusions in "Distribution of the Angle Between Two Random Vectors in n-dimensional Space" and "The Amazing Johnson-Lindenstrauss Lemma: Theory Edition".
Loss Analysis
For a language model, the final output is a token-by-token n-ary distribution, where n is the vocabulary size. Suppose we directly output a uniform distribution, meaning the probability of each token is 1/n; it is not difficult to calculate that the cross-entropy loss will be \log n. This implies that a reasonable initialization should not result in an initial loss significantly exceeding \log n, because \log n represents the most naive uniform distribution. Significantly exceeding \log n is equivalent to saying the model is far worse than a uniform distribution, which is like making intentional mistakes and is unreasonable.
So, why does this happen with shared embeddings? Suppose the initial embeddings are \{\boldsymbol{w}_1,\boldsymbol{w}_2,\cdots,\boldsymbol{w}_n\}. As mentioned earlier, the residual branches are close to zero in the initial stage, so for an input token i, the model output is the embedding \boldsymbol{w}_i after normalization. Common normalization methods are Layer Norm or RMS Norm. Since the initialization distribution is zero-mean, Layer Norm and RMS Norm are roughly equivalent, so the output is: \frac{\boldsymbol{w}_i}{\Vert\boldsymbol{w}_i\Vert \big/\sqrt{d}} = \frac{\boldsymbol{w}_i}{\sigma} Next, reusing the embeddings, taking the dot product and then the Softmax, the distribution established is essentially: p(j|i) = \frac{e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_j / \sigma}}{\sum\limits_k e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_k / \sigma}} The corresponding loss function is: -\log p(j|i) = \log \sum\limits_k e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_k / \sigma} - \boldsymbol{w}_i\cdot \boldsymbol{w}_j \big/ \sigma The language model task is to predict the next token, and we know that the proportion of repeated words in natural sentences is very small, so we can basically assume j\neq i. Then, according to result \eqref{eq:dot}, we have \boldsymbol{w}_i\cdot \boldsymbol{w}_j\approx 0. Therefore, the initial loss function is: -\log p(j|i) \approx \log \sum_k e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_k / \sigma}=\log \left(e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_i / \sigma} + \sum\limits_{k|k\neq i} e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_k / \sigma}\right)\approx\log \left(e^{d \sigma} + (n-1)\right) \label{eq:loss} The second \approx again uses equations \eqref{eq:norm} and \eqref{eq:dot}. Common initialization variances \sigma^2 are either a constant or 1/d (in which case e^{d \sigma}=e^{\sqrt{d}}). Regardless of which one it is, when d is large, e^{d \sigma} dominates, and the loss will be on the order of \log e^{d\sigma}=d\sigma, which easily exceeds the \log n of a uniform distribution.
Some Countermeasures
Based on the derived results, we can design some targeted countermeasures. A relatively straightforward solution is to adjust the initialization. According to equation \eqref{eq:loss}, we only need to make e^{d\sigma}=n, then the initial loss will be on the order of \log n. This means the standard deviation of the initialization should be changed to \sigma=(\log n)/d.
Generally, we hope that the initialization variance of parameters is as large as possible so that gradients are less likely to underflow, and \sigma=(\log n)/d can sometimes seem too small. To this end, we can consider another approach: clearly, the reason equation \eqref{eq:loss} is too large is the appearance of e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_i / \sigma}. Since the two \boldsymbol{w}_i are the same, their dot product becomes the squared norm, which becomes very large. If we can make them different, this dominant term will not appear.
The simplest method, naturally, is to simply not share embeddings. In this case, we have e^{\boldsymbol{w}_i\cdot \boldsymbol{v}_i / \sigma} instead of e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_i / \sigma}. Using \eqref{eq:dot} instead of \eqref{eq:norm} as an approximation, equation \eqref{eq:loss} asymptotically approaches \log n. If we still want to keep shared embeddings, we can add an orthogonally initialized projection layer after the final normalization. Thus, e^{\boldsymbol{w}_i\cdot \boldsymbol{w}_i / \sigma} becomes e^{(\boldsymbol{w}_i\boldsymbol{P})\cdot \boldsymbol{w}_i / \sigma}. According to the Johnson-Lindenstrauss Lemma, a vector after random projection is approximately an independent vector, so it approximates the non-shared case. This is actually BERT’s solution. Specifically, this projection layer can also be generalized by adding a bias and an activation function.
If one does not want to introduce any extra parameters at all, one can consider "shuffling" the dimensions of \boldsymbol{w}_i after normalization, for example: \mathcal{S}[\boldsymbol{w}] = \boldsymbol{w}[d/2:] \circ \boldsymbol{w}[:d/2] where \circ is the concatenation operation. Then \mathcal{S}[\boldsymbol{w}_i] and \boldsymbol{w}_i are nearly orthogonal, and their dot product is naturally approximately 0. This is equivalent to (in the initial stage) splitting the original n\times d embedding matrix into two n\times (d/2) matrices and constructing a 2-gram model without shared embeddings. Additionally, we can consider other shuffling operations, such as the reshape-transpose-reshape operation in ShuffleNet.
In the author’s experiments, directly changing the initialization standard deviation to \sigma=(\log n)/d resulted in the slowest convergence speed. The convergence speeds of the other methods were similar. As for the final performance, all methods seemed to be roughly the same.
Summary
This article revisited the operation of sharing embedding weights at the output of language models, derived the possibility that directly reusing embeddings for output projection might lead to excessive loss, and explored several solutions.
Original article address: https://kexue.fm/archives/9698
For more details on reprinting, please refer to: "Scientific Space FAQ"