Yesterday, I discovered a new paper on Arxiv from Google titled “Symbolic Discovery of Optimization Algorithms.” At first glance, it didn’t seem particularly interesting, as there have been many similar works, most of which yield lackluster results. However, upon closer reading, I found it to be quite remarkable. Through thousands of TPU hours of compute combined with human intervention, the authors discovered an optimizer that is faster and more memory-efficient, named Lion (EvoLved Sign Momentum; I have to complain that this name is quite a stretch). They conducted extensive experiments on tasks such as image classification, image-text matching, diffusion models, and language model pre-training and fine-tuning. In most tasks, Lion showed better results than currently mainstream optimizers like AdamW.
Saving memory while achieving better results truly feels like having one’s cake and eating it too. What kind of optimizer can possess such powerful performance? Let’s appreciate the results of the paper together.
Results First
This article is primarily concerned with the discovered optimizer itself, so we will not discuss the details of the search process. Interested readers can refer to the original paper. The update process for the Lion optimizer is: \text{Lion} := \left\{ \begin{aligned} &\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + (1 - \beta_1) \boldsymbol{g}_t\big) \\ &\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \textcolor{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\ &\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + (1 - \beta_2) \boldsymbol{g}_t \end{aligned} \right. where \boldsymbol{g}_t = \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{t-1}) is the gradient of the loss function, and \text{sign} is the sign function, which turns positive numbers into 1 and negative numbers into -1. We can compare this with the update process of the currently mainstream optimizer AdamW: \text{Adam}\textcolor{skyblue}{\text{W}} := \left\{ \begin{aligned} &\boldsymbol{m}_t = \beta_1 \boldsymbol{m}_{t-1} + (1 - \beta_1) \boldsymbol{g}_t\\ &\boldsymbol{v}_t = \beta_2 \boldsymbol{v}_{t-1} + (1 - \beta_2) \boldsymbol{g}_t^2\\ &\hat{\boldsymbol{m}}_t = \boldsymbol{m}_t / (1 - \beta_1^t)\\ &\hat{\boldsymbol{v}}_t = \boldsymbol{v}_t / (1 - \beta_2^t)\\ &\boldsymbol{u}_t = \hat{\boldsymbol{m}}_t / (\sqrt{\hat{\boldsymbol{v}}_t} + \epsilon)\\ &\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \textcolor{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \end{aligned} \right. The contrast is obvious. Compared to AdamW, Lion has fewer parameters (missing \epsilon), caches one fewer set of parameters \boldsymbol{v} (thus saving VRAM), and removes the division and square root operations, which are the most computationally expensive parts of the AdamW update process (thus making it faster).
Prior to this, the optimizer most similar to Lion was likely SIGNUM, whose update process is: \text{SIGNUM} := \left\{ \begin{aligned} &\boldsymbol{m}_t = \beta \boldsymbol{m}_{t-1} + (1 - \beta) \boldsymbol{g}_t \\ &\boldsymbol{u}_t = \text{sign}\big(\boldsymbol{m}_t\big) \\ &\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t \boldsymbol{u}_t \end{aligned} \right. Like Lion, SIGNUM also uses the sign function to process the update amount and is even more simplified (equivalent to a special case of Lion where \beta_1 = \beta_2 and \lambda_t = 0). However, unfortunately, SIGNUM did not achieve better results; its original design intention was merely to reduce transmission costs in distributed computing. Lion’s update rules are different, especially in that the momentum update is placed after the variable update, and it has demonstrated its advantage in effectiveness through sufficient experimentation.
Paper Experiments
As mentioned at the beginning, Lion has been tested on a considerable number of tasks. The experimental results are numerous; below are some key results.
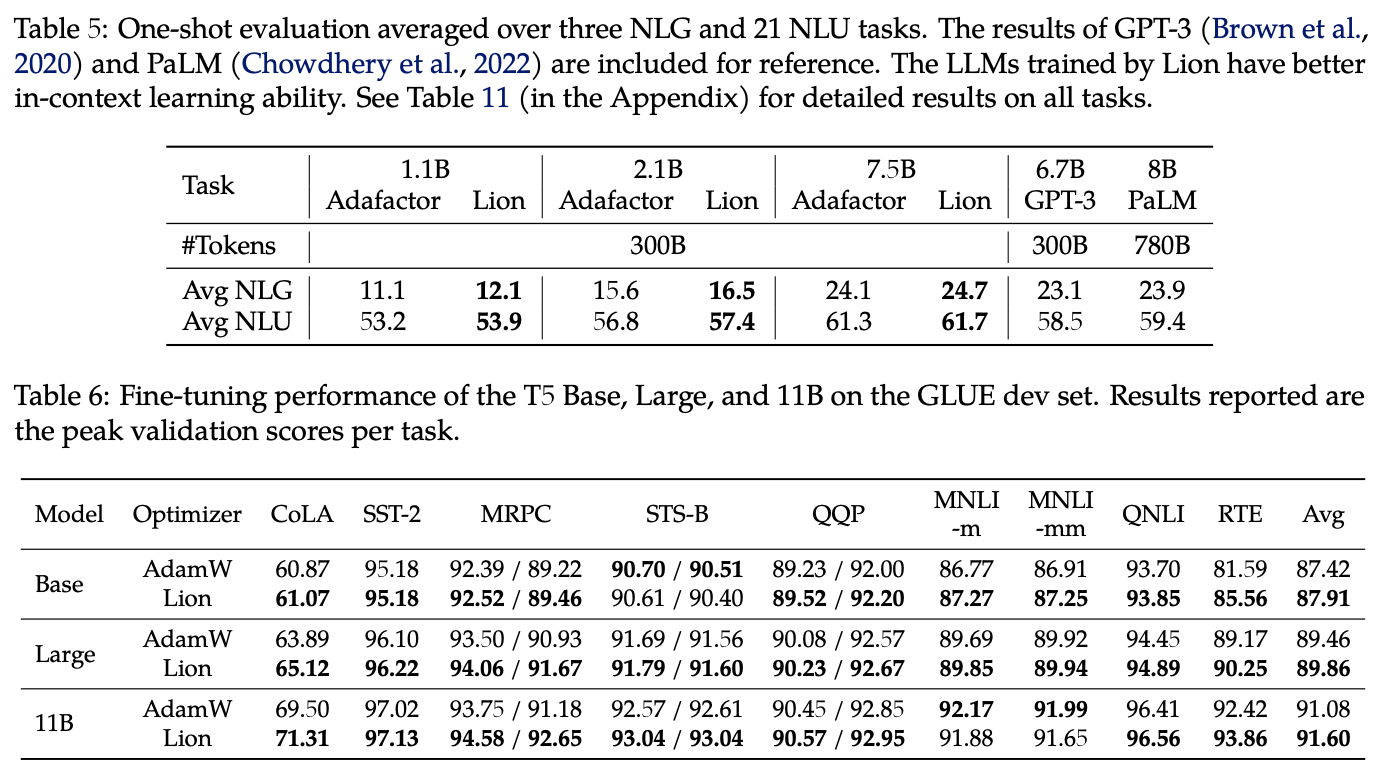
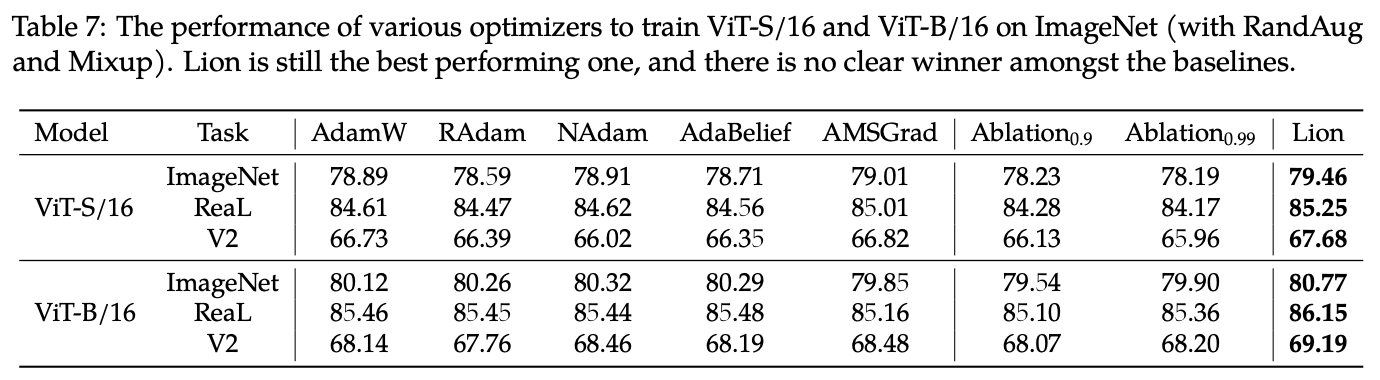
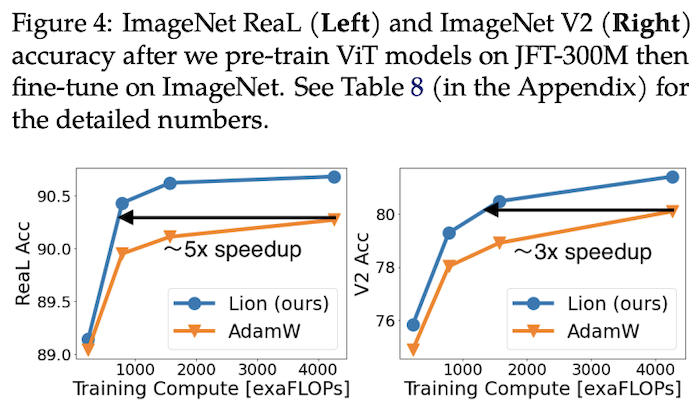
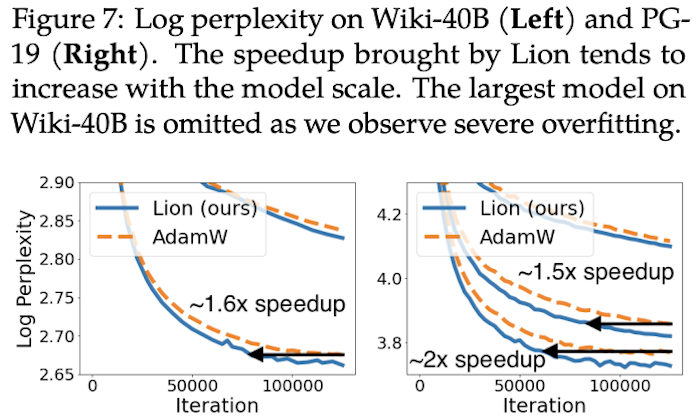
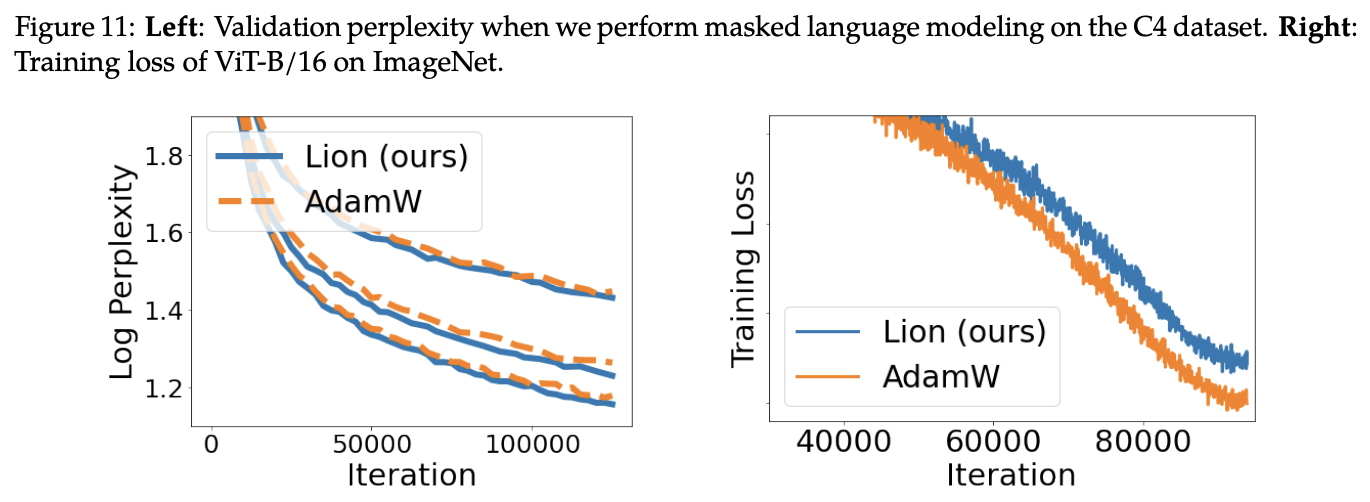
Hyperparameter Settings
Seeing such impressive results in the paper, I was eager to try it out. Before running experiments, it is naturally necessary to understand the settings for each hyperparameter. First are \beta_1, \beta_2. The result searched automatically in the original paper is \beta_1=0.9, \beta_2=0.99, and this combination was reused in most experiments. However, on NLP tasks, the combination \beta_1=0.95, \beta_2=0.98 was used (detailed experimental configurations are in Table 12 on the last page of the paper).
The more critical hyperparameters are the learning rate \eta and the weight decay rate \lambda. Since the absolute value of each component of Lion’s update \boldsymbol{u} is 1, which is typically larger than AdamW, the learning rate should be reduced by more than 10 times to obtain roughly the same update magnitude. Furthermore, because the learning rate is reduced, the weight decay rate should be increased by a corresponding factor to keep the magnitude of weight decay constant. The last page of the original paper provides reference values for hyperparameters in various experiments: for small models (Base level), \eta = 3 \times 10^{-4} and \lambda = 0.01 were used; for large models (over 1 billion parameters), the learning rate was appropriately reduced to \eta = 2 \times 10^{-4} or even \eta = 10^{-4}.
In fact, we previously derived a combination scheme for learning rate and weight decay in “Some ’Alchemy Strategies’ Derived from the Amos Optimizer.” It is most convenient to set them according to this scheme. In that scheme, the update is written as: \boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - (\alpha_t \boldsymbol{u}_t + \rho_t \boldsymbol{\theta}_t) where \alpha_t \approx \frac{\alpha_0 \Vert \boldsymbol{\varepsilon}_0 \Vert}{\Vert \boldsymbol{u}_t \Vert} \frac{1}{\kappa t + 1}, \quad \rho_t \approx \frac{\alpha_0^2}{2q} \frac{1}{\kappa t + 1} Here, \boldsymbol{u}_t is the original update amount; \alpha_0 is the relative size of parameter change (initial stage), generally around 10^{-3}; q is a hyperparameter, which can be set to 1; \kappa is a hyperparameter controlling the decay speed.
Since \boldsymbol{u}_t undergoes a \text{sign} operation, \Vert \boldsymbol{u}_t \Vert = \sqrt{k}, where k is the dimension of the parameters. \Vert \boldsymbol{\varepsilon}_0 \Vert \approx \sqrt{k}\sigma, where \sigma is the scale of parameter variation. For multiplicative matrices, \sigma^2 is its initialization variance. Thus, after a series of simplifications, we have: \alpha_t \approx \frac{\alpha_0 \sigma}{\kappa t + 1}, \quad \rho_t \approx \frac{\alpha_0^2}{2(\kappa t + 1)} Here \alpha_t is the previous \eta_t, and \lambda_t = \rho_t / \alpha_t = \alpha_0 / 2\sigma. According to BERT base’s d=768, the initialization variance is roughly 1/d, so \sigma = \sqrt{1/d} \approx 0.036. If \alpha_0 is taken as 1.11 \times 10^{-3}, then the learning rate is approximately 4 \times 10^{-5} and the decay rate is approximately 0.015. In my own MLM pre-training experiments, these two combinations worked well.
Personal Implementation: https://github.com/bojone/bert4keras
Extended Thinking
Overall, Lion’s performance is noteworthy. In both the original paper and my own experiments, it holds its own against AdamW. Combined with its faster speed and lower memory usage, it is foreseeable that it will have a place among future mainstream optimizers.
Since Adam was proposed, it has become the default optimizer for many models due to its fast convergence. Some scholars even suggest that this phenomenon has led to an evolutionary effect: all model improvements are moving in a direction favorable to Adam. In other words, because we chose Adam, we might have discarded many changes that are actually effective but ineffective on Adam. For a detailed evaluation, refer to “NEURAL NETWORKS (MAYBE) EVOLVED TO MAKE ADAM THE BEST OPTIMIZER.” Therefore, discovering an optimizer simpler and more effective than Adam is a significant achievement, even if it was found using massive compute.
Readers might wonder: why does Lion achieve better generalization? The original paper explains that the \text{sign} operation introduces extra noise (compared to precise floating-point values), which helps the model enter flatter (though not necessarily lower) loss regions, leading to better generalization. To verify this, the authors compared the robustness of model weights trained by AdamW and Lion; the results showed that Lion’s robustness was better. Theoretically, this only proves Lion enters flatter regions, not that the \text{sign} operation is the cause. However, Adam has been out for many years and its mechanism is still not fully understood, so we shouldn’t be too critical of the newly proposed Lion.
My guess is that Lion treats every component equally through the \text{sign} operation, allowing the model to fully utilize every component, thus achieving better generalization. In SGD, the update size is proportional to the gradient; however, some components might have small gradients just because they weren’t initialized well, not because they are unimportant. Lion’s \text{sign} operation provides an opportunity for every parameter to "recover vitality." In fact, it can be proven that Adam’s early updates are also close to \text{sign}, only deviating as training progresses.
Is Lion perfect? Obviously not. For instance, the original paper points out that it performs worse than AdamW with small batch sizes (less than 64). This is understandable: \text{sign} already introduces noise, and small batch sizes increase it further. Noise must be moderate; too much can degrade performance. Also, because \text{sign} increases noise, the loss might diverge if parameters are set incorrectly; in such cases, one can try introducing or increasing Warmup steps. Additionally, Lion still needs to cache momentum parameters, so its memory usage is higher than AdaFactor. Whether this can be further optimized is currently unknown.
Conclusion
This article introduced the new optimizer Lion proposed by Google, which was derived through massive compute search combined with human intervention. Compared to the mainstream AdamW, it is faster and more memory-efficient, and extensive experiments show it performs as well as or better than AdamW on most tasks.
When reprinting, please include the original link: https://kexue.fm/archives/9473
For more detailed reprinting matters, please refer to: Scientific Space FAQ