So far, I have provided two derivations of the generative diffusion model DDPM. One is the popular analogy scheme in "Discussion on Generative Diffusion Models (I): DDPM = Demolishing + Building", and the other is the Variational Autoencoder (VAE) scheme in "Discussion on Generative Diffusion Models (II): DDPM = Autoregressive VAE". Both schemes have their own characteristics: the former is more straightforward and easy to understand but lacks theoretical extension and quantitative understanding, while the latter is more theoretically complete but somewhat formal and less intuitive.
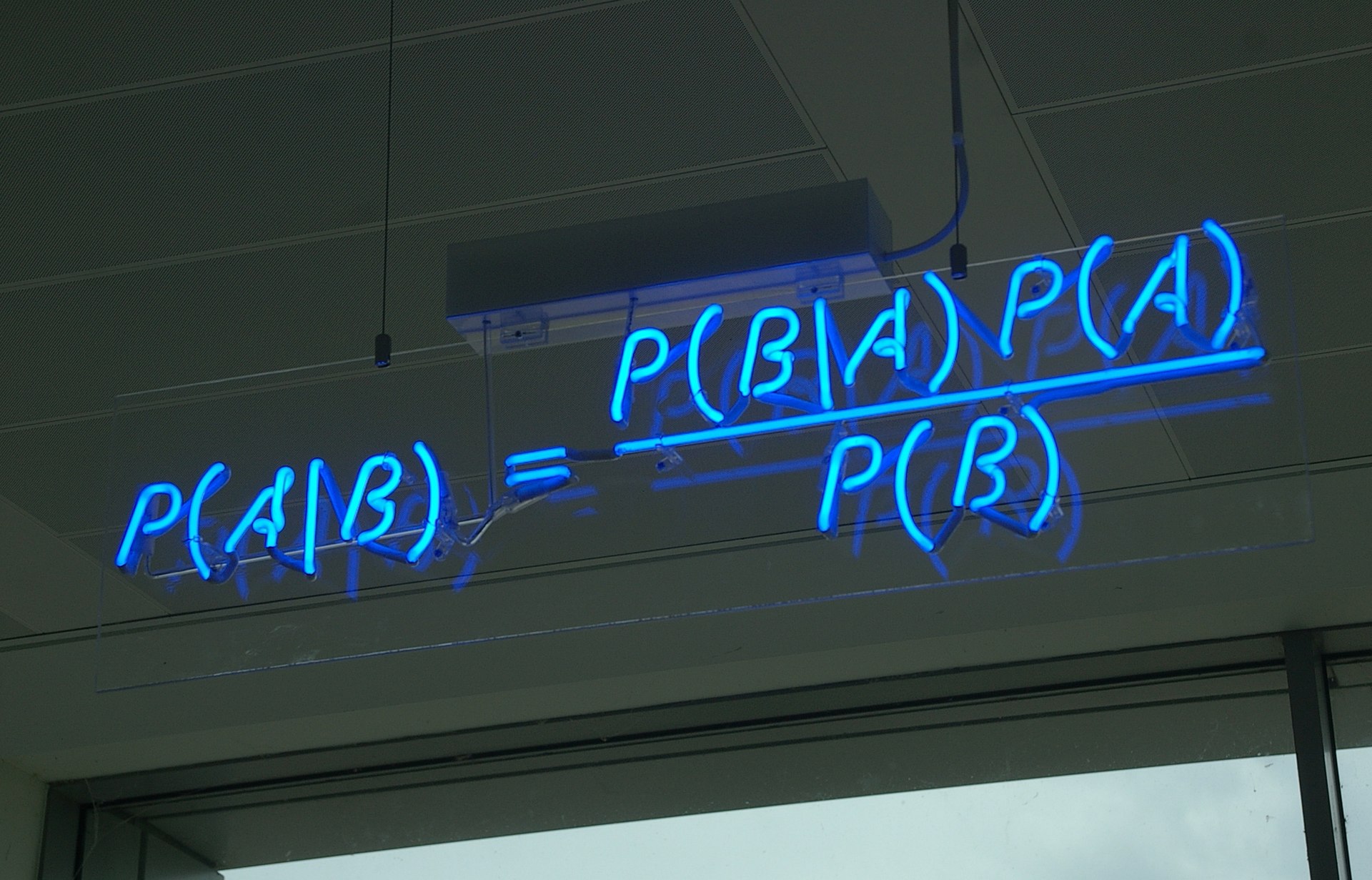
In this article, we will share another derivation of DDPM, which mainly utilizes Bayes’ theorem to simplify calculations. The entire process of "deliberation" is quite profound and enlightening. Not only that, it is also closely related to the DDIM model that we will introduce later.
Model Landscape
To recap, DDPM models the following transformation process: \boldsymbol{x} = \boldsymbol{x}_0 \rightleftharpoons \boldsymbol{x}_1 \rightleftharpoons \boldsymbol{x}_2 \rightleftharpoons \cdots \rightleftharpoons \boldsymbol{x}_{T-1} \rightleftharpoons \boldsymbol{x}_T = \boldsymbol{z} Where the forward process gradually transforms the sample data \boldsymbol{x} into random noise \boldsymbol{z}, and the reverse process gradually transforms the random noise \boldsymbol{z} into sample data \boldsymbol{x}. The reverse process is the "generative model" we wish to obtain.
The forward process is simple; each step is: \boldsymbol{x}_t = \alpha_t \boldsymbol{x}_{t-1} + \beta_t \boldsymbol{\varepsilon}_t,\quad \boldsymbol{\varepsilon}_t\sim\mathcal{N}(\boldsymbol{0}, \boldsymbol{I}) Or written as p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})=\mathcal{N}(\boldsymbol{x}_t;\alpha_t \boldsymbol{x}_{t-1},\beta_t^2 \boldsymbol{I}). Under the constraint \alpha_t^2 + \beta_t^2 = 1, we have: \begin{aligned} \boldsymbol{x}_t =&\, \alpha_t \boldsymbol{x}_{t-1} + \beta_t \boldsymbol{\varepsilon}_t \\ =&\, \alpha_t \big(\alpha_{t-1} \boldsymbol{x}_{t-2} + \beta_{t-1} \boldsymbol{\varepsilon}_{t-1}\big) + \beta_t \boldsymbol{\varepsilon}_t \\ =&\,\cdots\\ =&\,(\alpha_t\cdots\alpha_1) \boldsymbol{x}_0 + \underbrace{(\alpha_t\cdots\alpha_2)\beta_1 \boldsymbol{\varepsilon}_1 + (\alpha_t\cdots\alpha_3)\beta_2 \boldsymbol{\varepsilon}_2 + \cdots + \alpha_t\beta_{t-1} \boldsymbol{\varepsilon}_{t-1} + \beta_t \boldsymbol{\varepsilon}_t}_{\sim \mathcal{N}(\boldsymbol{0}, (1-\alpha_t^2\cdots\alpha_1^2)\boldsymbol{I})} \end{aligned} From this, we can derive p(\boldsymbol{x}_t|\boldsymbol{x}_0)=\mathcal{N}(\boldsymbol{x}_t;\bar{\alpha}_t \boldsymbol{x}_0,\bar{\beta}_t^2 \boldsymbol{I}), where \bar{\alpha}_t = \alpha_1\cdots\alpha_t and \bar{\beta}_t = \sqrt{1-\bar{\alpha}_t^2}.
What DDPM needs to do is to find p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) required for the reverse process from the above information. In this way, we can start from any \boldsymbol{x}_T=\boldsymbol{z} and step-by-step sample \boldsymbol{x}_{T-1}, \boldsymbol{x}_{T-2}, \dots, \boldsymbol{x}_1, finally obtaining the randomly generated sample data \boldsymbol{x}_0=\boldsymbol{x}.
Invoking Bayes
Now we invoke the great Bayes’ theorem. In fact, directly according to Bayes’ theorem, we have: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) = \frac{p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})p(\boldsymbol{x}_{t-1})}{p(\boldsymbol{x}_t)} \label{eq:bayes} However, we do not know the expressions for p(\boldsymbol{x}_{t-1}) and p(\boldsymbol{x}_t), so this path is blocked. But we can settle for the next best thing and use Bayes’ theorem given the condition \boldsymbol{x}_0: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) = \frac{p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_0)}{p(\boldsymbol{x}_t|\boldsymbol{x}_0)} This modification is natural because p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1}), p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_0), and p(\boldsymbol{x}_t|\boldsymbol{x}_0) are all known. Therefore, the above equation is computable. Substituting their respective expressions, we get: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) = \mathcal{N}\left(\boldsymbol{x}_{t-1};\frac{\alpha_t\bar{\beta}_{t-1}^2}{\bar{\beta}_t^2}\boldsymbol{x}_t + \frac{\bar{\alpha}_{t-1}\beta_t^2}{\bar{\beta}_t^2}\boldsymbol{x}_0,\frac{\bar{\beta}_{t-1}^2\beta_t^2}{\bar{\beta}_t^2} \boldsymbol{I}\right) \label{eq:p-xt-x0}
Derivation: The derivation of the above formula is not difficult; it is just a routine expansion and reorganization. Of course, we can find some tricks to speed up the calculation. First, by substituting the expressions, we find that in the exponent part (excluding the -1/2 factor), the result is: \frac{\Vert \boldsymbol{x}_t - \alpha_t \boldsymbol{x}_{t-1}\Vert^2}{\beta_t^2} + \frac{\Vert \boldsymbol{x}_{t-1} - \bar{\alpha}_{t-1}\boldsymbol{x}_0\Vert^2}{\bar{\beta}_{t-1}^2} - \frac{\Vert \boldsymbol{x}_t - \bar{\alpha}_t \boldsymbol{x}_0\Vert^2}{\bar{\beta}_t^2} It is quadratic with respect to \boldsymbol{x}_{t-1}, so the final distribution must also be a normal distribution. We only need to find its mean and covariance. It is not hard to see that the coefficient of the \Vert \boldsymbol{x}_{t-1}\Vert^2 term in the expansion is: \frac{\alpha_t^2}{\beta_t^2} + \frac{1}{\bar{\beta}_{t-1}^2} = \frac{\alpha_t^2\bar{\beta}_{t-1}^2 + \beta_t^2}{\bar{\beta}_{t-1}^2 \beta_t^2} = \frac{\alpha_t^2(1-\bar{\alpha}_{t-1}^2) + \beta_t^2}{\bar{\beta}_{t-1}^2 \beta_t^2} = \frac{1-\bar{\alpha}_t^2}{\bar{\beta}_{t-1}^2 \beta_t^2} = \frac{\bar{\beta}_t^2}{\bar{\beta}_{t-1}^2 \beta_t^2} So the reorganized result must be in the form of \frac{\bar{\beta}_t^2}{\bar{\beta}_{t-1}^2 \beta_t^2}\Vert \boldsymbol{x}_{t-1} - \tilde{\boldsymbol{\mu}}(\boldsymbol{x}_t, \boldsymbol{x}_0)\Vert^2, which means the covariance matrix is \frac{\bar{\beta}_{t-1}^2 \beta_t^2}{\bar{\beta}_t^2}\boldsymbol{I}. On the other hand, taking out the linear term coefficient gives -2\left(\frac{\alpha_t}{\beta_t^2}\boldsymbol{x}_t + \frac{\bar{\alpha}_{t-1}}{\bar{\beta}_{t-1}^2}\boldsymbol{x}_0 \right). Dividing by \frac{-2\bar{\beta}_t^2}{\bar{\beta}_{t-1}^2 \beta_t^2}, we obtain: \tilde{\boldsymbol{\mu}}(\boldsymbol{x}_t, \boldsymbol{x}_0)=\frac{\alpha_t\bar{\beta}_{t-1}^2}{\bar{\beta}_t^2}\boldsymbol{x}_t + \frac{\bar{\alpha}_{t-1}\beta_t^2}{\bar{\beta}_t^2}\boldsymbol{x}_0 This provides all the information for p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0), and the result is exactly Equation [eq:p-xt-x0].
Denoising Process
Now we have obtained p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0). It has an explicit solution, but it is not the final answer we want because we only want to predict \boldsymbol{x}_{t-1} through \boldsymbol{x}_t without relying on \boldsymbol{x}_0, which is the final result we want to generate. Next, a "whimsical" idea is:
If we can predict \boldsymbol{x}_0 through \boldsymbol{x}_t, can’t we eliminate \boldsymbol{x}_0 in p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) so that it only depends on \boldsymbol{x}_t?
Let’s do it. We use \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t) to estimate \boldsymbol{x}_0, with the loss function being \Vert \boldsymbol{x}_0 - \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t)\Vert^2. After training is completed, we assume: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) \approx p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\bar{\boldsymbol{\mu}}(\boldsymbol{x}_t)) = \mathcal{N}\left(\boldsymbol{x}_{t-1}; \frac{\alpha_t\bar{\beta}_{t-1}^2}{\bar{\beta}_t^2}\boldsymbol{x}_t + \frac{\bar{\alpha}_{t-1}\beta_t^2}{\bar{\beta}_t^2}\bar{\boldsymbol{\mu}}(\boldsymbol{x}_t),\frac{\bar{\beta}_{t-1}^2\beta_t^2}{\bar{\beta}_t^2} \boldsymbol{I}\right) \label{eq:p-xt} In \Vert \boldsymbol{x}_0 - \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t)\Vert^2, \boldsymbol{x}_0 represents the original data and \boldsymbol{x}_t represents the noisy data, so this is actually training a denoising model. This is the meaning of the first "D" in DDPM (Denoising).
Specifically, p(\boldsymbol{x}_t|\boldsymbol{x}_0)=\mathcal{N}(\boldsymbol{x}_t;\bar{\alpha}_t \boldsymbol{x}_0,\bar{\beta}_t^2 \boldsymbol{I}) means \boldsymbol{x}_t = \bar{\alpha}_t \boldsymbol{x}_0 + \bar{\beta}_t \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon}\sim\mathcal{N}(\boldsymbol{0}, \boldsymbol{I}), or written as \boldsymbol{x}_0 = \frac{1}{\bar{\alpha}_t}\left(\boldsymbol{x}_t - \bar{\beta}_t \boldsymbol{\varepsilon}\right). This inspires us to parameterize \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t) as: \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t) = \frac{1}{\bar{\alpha}_t}\left(\boldsymbol{x}_t - \bar{\beta}_t \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)\right) \label{eq:bar-mu} At this point, the loss function becomes: \Vert \boldsymbol{x}_0 - \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t)\Vert^2 = \frac{\bar{\beta}_t^2}{\bar{\alpha}_t^2}\left\Vert\boldsymbol{\varepsilon} - \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\bar{\alpha}_t \boldsymbol{x}_0 + \bar{\beta}_t \boldsymbol{\varepsilon}, t)\right\Vert^2 Omitting the preceding coefficient, we get the loss function used in the original DDPM paper. It can be seen that this article directly derives the denoising process from \boldsymbol{x}_t to \boldsymbol{x}_0, rather than deriving it through the denoising process from \boldsymbol{x}_t to \boldsymbol{x}_{t-1} plus integral transformation as in the previous two articles. In comparison, the derivation in this article is more direct.
On the other hand, substituting Equation [eq:bar-mu] into Equation [eq:p-xt] and simplifying, we get: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) \approx p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\bar{\boldsymbol{\mu}}(\boldsymbol{x}_t)) = \mathcal{N}\left(\boldsymbol{x}_{t-1}; \frac{1}{\alpha_t}\left(\boldsymbol{x}_t - \frac{\beta_t^2}{\bar{\beta}_t}\boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)\right),\frac{\bar{\beta}_{t-1}^2\beta_t^2}{\bar{\beta}_t^2} \boldsymbol{I}\right) This is the distribution used in the reverse sampling process, and the variance used in the sampling process is also determined. At this point, the derivation of DDPM is complete! (Note: For the sake of smoothness in derivation, \boldsymbol{\epsilon}_{\boldsymbol{\theta}} in this article is different from the previous two introductions, but consistent with the original DDPM paper.)
Derivation: The main difficulty in substituting Equation [eq:bar-mu] into Equation [eq:p-xt] is calculating: \begin{aligned} \frac{\alpha_t\bar{\beta}_{t-1}^2}{\bar{\beta}_t^2} + \frac{\bar{\alpha}_{t-1}\beta_t^2}{\bar{\alpha}_t\bar{\beta}_t^2} =&\, \frac{\alpha_t\bar{\beta}_{t-1}^2 + \beta_t^2/\alpha_t}{\bar{\beta}_t^2} = \frac{\alpha_t^2(1-\bar{\alpha}_{t-1}^2) + \beta_t^2}{\alpha_t\bar{\beta}_t^2} = \frac{1-\bar{\alpha}_t^2}{\alpha_t\bar{\beta}_t^2} = \frac{1}{\alpha_t} \end{aligned}
Prediction-Correction
I wonder if the reader has noticed an interesting point: what we want to do is slowly transform \boldsymbol{x}_T into \boldsymbol{x}_0. However, when we use p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) to approximate p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t), we include the step of "using \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t) to predict \boldsymbol{x}_0". If we could predict it accurately, wouldn’t we be able to reach the goal in one step? Why do we still need step-by-step sampling?
The reality is that "using \bar{\boldsymbol{\mu}}(\boldsymbol{x}_t) to predict \boldsymbol{x}_0" will certainly not be very accurate, at least not in the first many steps. It only plays a forward-looking predictive role, and then we only use p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) to advance a small step. This is the "prediction-correction" idea in many numerical algorithms, where we use a rough solution to push forward many steps, and then use this rough result to advance the final result by a small step, thereby gradually obtaining a more refined solution.
From this, we can also think of the "Lookahead Optimizer: k steps forward, 1 step back" proposed by Hinton three years ago. It also includes two parts: prediction (k steps forward) and correction (1 step back). The original paper interprets it as the combination of "Fast" and "Slow" weights; the fast weight is the result obtained by prediction, and the slow weight is the correction result based on the prediction. If we wish, we can also interpret the "prediction-correction" process of DDPM in the same way.
Remaining Issues
Finally, in the section on using Bayes’ theorem, we said that Equation [eq:bayes] cannot be used directly because p(\boldsymbol{x}_{t-1}) and p(\boldsymbol{x}_t) are unknown. According to the definition, we have: p(\boldsymbol{x}_t) = \int p(\boldsymbol{x}_t|\boldsymbol{x}_0)\tilde{p}(\boldsymbol{x}_0)d\boldsymbol{x}_0 Where p(\boldsymbol{x}_t|\boldsymbol{x}_0) is known, but the data distribution \tilde{p}(\boldsymbol{x}_0) cannot be known in advance, so it cannot be calculated. However, there are two special cases where both can be calculated directly. We will supplement the calculation here, and the results happen to be the answer to the variance selection problem left over from the previous article.
The first example is when the entire dataset has only one sample. Without loss of generality, assume the sample is \boldsymbol{0}. In this case, \tilde{p}(\boldsymbol{x}_0) is the Dirac distribution \delta(\boldsymbol{x}_0), and p(\boldsymbol{x}_t)=p(\boldsymbol{x}_t|\boldsymbol{0}) can be calculated directly. Then, substituting into Equation [eq:bayes], we find that the result is exactly the special case of p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t,\boldsymbol{x}_0) taking \boldsymbol{x}_0=\boldsymbol{0}, namely: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) = p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\boldsymbol{0}) = \mathcal{N}\left(\boldsymbol{x}_{t-1};\frac{\alpha_t\bar{\beta}_{t-1}^2}{\bar{\beta}_t^2}\boldsymbol{x}_t,\frac{\bar{\beta}_{t-1}^2\beta_t^2}{\bar{\beta}_t^2} \boldsymbol{I}\right) We are mainly concerned that its variance is \frac{\bar{\beta}_{t-1}^2\beta_t^2}{\bar{\beta}_t^2}, which is one of the choices for sampling variance.
The second example is when the dataset follows a standard normal distribution, i.e., \tilde{p}(\boldsymbol{x}_0)=\mathcal{N}(\boldsymbol{x}_0;\boldsymbol{0},\boldsymbol{I}). Previously, we said that p(\boldsymbol{x}_t|\boldsymbol{x}_0)=\mathcal{N}(\boldsymbol{x}_t;\bar{\alpha}_t \boldsymbol{x}_0,\bar{\beta}_t^2 \boldsymbol{I}) means \boldsymbol{x}_t = \bar{\alpha}_t \boldsymbol{x}_0 + \bar{\beta}_t \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon}\sim\mathcal{N}(\boldsymbol{0}, \boldsymbol{I}). Since we also assume \boldsymbol{x}_0\sim\mathcal{N}(\boldsymbol{0}, \boldsymbol{I}), by the additivity of normal distributions, \boldsymbol{x}_t also follows a standard normal distribution. After substituting the probability density of the standard normal distribution into Equation [eq:bayes], the result of the exponent part (excluding the -1/2 factor) is: \frac{\Vert \boldsymbol{x}_t - \alpha_t \boldsymbol{x}_{t-1}\Vert^2}{\beta_t^2} + \Vert \boldsymbol{x}_{t-1}\Vert^2 - \Vert \boldsymbol{x}_t\Vert^2 Similar to the process of deriving p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t,\boldsymbol{x}_0), we can obtain that the above exponent corresponds to: p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t) = \mathcal{N}\left(\boldsymbol{x}_{t-1};\alpha_t\boldsymbol{x}_t,\beta_t^2 \boldsymbol{I}\right) We are also mainly concerned that its variance is \beta_t^2, which is another choice for sampling variance.
Summary
This article shares a derivation of DDPM that has a sense of "deliberation." It uses Bayes’ theorem to directly derive the reverse generation process, which is more direct than the previous "demolishing-building" analogy and variational inference understanding. At the same time, it is more enlightening and closely related to the DDIM to be introduced next.