Recently, a paper on arXiv titled "EXACT: How to Train Your Accuracy" caught my interest. As the name suggests, it introduces how to train a model directly using accuracy as the training objective. Since I have previously conducted some analysis on this topic—such as in "Random Talk on Function Smoothing: Differentiable Approximation of Non-differentiable Functions" and "Revisiting Class Imbalance: Contrast and Connection between Weight Adjustment and Loss Modification"—I was able to quickly finish reading the paper based on my prior research experience. I have written this summary and included some of my recent new thoughts on this subject.
Inaccurate Examples
At the beginning of the paper, the authors point out that the classification loss functions we commonly use, such as Cross-Entropy or Hinge Loss (as in SVM), do not fit the final evaluation metric—accuracy—very well. To illustrate this, the paper provides a very simple example: suppose there are only three data points \{(-0.25, -1), (0, -1), (0.25, 1)\}, where -1 and 1 represent the negative and positive classes, respectively. The model to be fitted is f(x) = x - b, where b is a parameter, and we hope to predict the category via \text{sign}(f(x)). If we use "sigmoid + Cross-Entropy," the loss function is -\log \frac{1}{1+e^{-l \cdot f(x)}}, where (x, l) represents a pair of labeled data. If we use Hinge Loss, it is \max(0, 1 - l \cdot f(x)).
Since this is a one-dimensional model, we can directly perform a grid search for its optimal solution. It can be found that if "sigmoid + Cross-Entropy" is used, the minimum of the loss function is reached at b=0.7. If Hinge Loss is used, then b \in [0.75, 1]. However, to achieve perfect classification via \text{sign}(f(x)), b must be in the range (0, 0.25). This demonstrates the inconsistency between Cross-Entropy or Hinge Loss and the final evaluation metric, accuracy.
While this seems like a concise and elegant example, I believe it does not reflect reality. The biggest issue is the model’s temperature parameter. Generally, models appear as f(x) = k(x - b) rather than f(x) = x - b. Deliberately removing the temperature parameter to construct an unrealistic counterexample is unconvincing. In fact, after adding an adjustable temperature parameter, both of these losses can learn the correct answer. Even more unfairly, when the authors later propose their own solution, EXACT, it includes a built-in temperature parameter, which is a key component. In other words, in this example, EXACT performs better than the other two losses purely because EXACT has a temperature parameter.
Old Wine in New Bottles
Next, let’s look at the proposed scheme—EXACT (EXpected ACcuracy opTimization). In hindsight, EXACT is somewhat mysterious because the authors directly redefine a conditional probability distribution p(y|x) from the perspective of reparameterization without much explanation: p(y|x) = P\left(y = \mathop{\text{argmax}}_i \frac{\mu(x)}{\sigma(x)} + \varepsilon\right) where \mu(x) is a vector network, \sigma(x) is a scalar network, and \varepsilon has the same dimension as \mu(x), with each component sampled independently and identically from \sim \mathcal{N}(0,1). Regarding the practice of defining probability distributions through reparameterization, we discussed this in the previous article "Constructing Discrete Probability Distributions from a Reparameterization Perspective", so I will not repeat it here.
Immediately following this, with this new p(y|x), the authors directly use -\mathbb{E}_{(x,y)\sim\mathcal{D}}[p(y|x)] \label{eq:soft-acc} as the loss function. The theoretical framework of the entire paper basically ends here.
From this, we can summarize the confusing aspects of EXACT. In the aforementioned article, we know that from a reparameterization perspective, the noise distribution corresponding to Softmax is the Gumbel distribution. EXACT replaces this with a Normal distribution, but what makes it better? Why would it be better? There is no explanation for this.
Furthermore, the negative of Equation [eq:soft-acc] is a smooth approximation of accuracy. This is already "widely known," but it is also a widely known conclusion that directly optimizing Equation [eq:soft-acc] under Softmax is usually inferior to optimizing Cross-Entropy. Now, it is just "old wine" (the same smooth approximation of accuracy) in a "new bottle" (a new method for constructing the probability distribution). Can there really be an improvement?
Experiments Hard to Reproduce
The original paper provides very striking experimental results, showing that EXACT is almost always SOTA (State-of-the-Art):
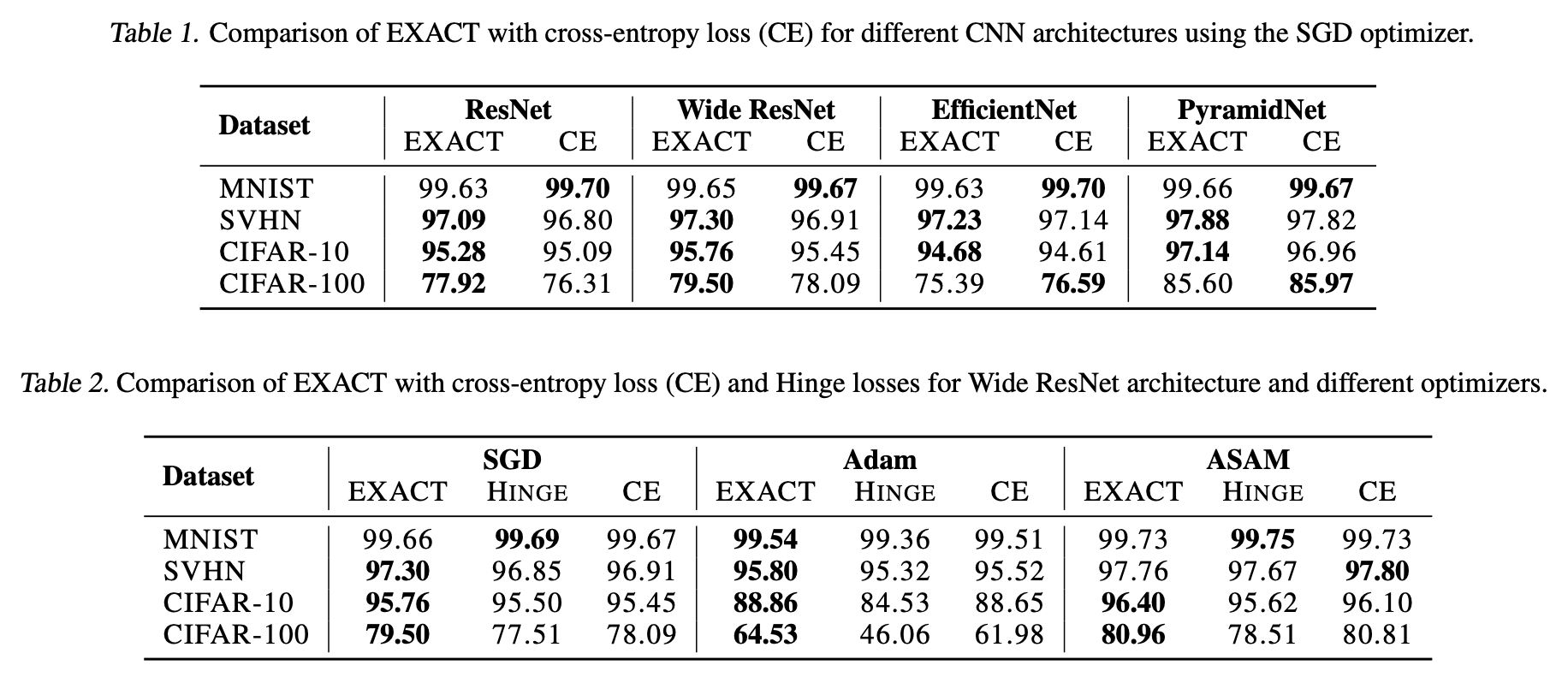
However, I attempted to implement EXACT based on my understanding and tested it on NLP tasks. The results showed that EXACT completely failed to reach the level of "Softmax + Cross-Entropy." Additionally, the original paper mentioned that optimizing -\log\mathbb{E}_{(x,y)\sim\mathcal{D}}[p(y|x)] would be better than Equation [eq:soft-acc], but my results showed that this variant could not even match Equation [eq:soft-acc]. Overall, my test conclusions are vastly different from those in the original paper.
Since the original paper has not yet released its source code, I cannot further judge the reliability of the paper’s experiments. However, from my theoretical understanding and preliminary experimental results, it is highly unlikely that directly optimizing Equation [eq:soft-acc] would achieve the same effect as optimizing Cross-Entropy. Simply modifying the way the probability distribution is constructed is unlikely to lead to a substantial improvement. If readers have new experimental results, further exchange and sharing are welcome.
A New Perspective
Numerically, Equation [eq:soft-acc] is indeed closer to accuracy than Cross-Entropy \mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p(y|x)]. But why does optimizing Cross-Entropy often yield better accuracy? I was previously puzzled by this as well. In "Revisiting Class Imbalance", I resorted to treating it as an "axiom," which was a matter of necessity.
Until one day, I suddenly realized a relationship: as training progresses, most p(y|x) will slowly approach 1. Thus, we can use the approximation \log x \approx x - 1 to get: \mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p(y|x)] \approx \mathbb{E}_{(x,y)\sim\mathcal{D}}[1 - p(y|x)] = 1 - \mathbb{E}_{(x,y)\sim\mathcal{D}}[p(y|x)] Thus, we can explain why optimizing Cross-Entropy also yields good accuracy. From the above formula, we find that in the middle and late stages of optimization, Cross-Entropy is basically equivalent to Equation [eq:soft-acc], which means it is also optimizing a smooth approximation of accuracy!
So, what is the advantage of Cross-Entropy over Equation [eq:soft-acc]? The difference lies in the gap between -\log p(y|x) and 1 - p(y|x) when p(y|x) \ll 1. When p(y|x) \ll 1 (i.e., the probability of the target class is very small), it means the classification is likely very inaccurate. In this case, -\log p(y|x) provides a result that tends toward infinity, while 1 - p(y|x) can at most provide a value of 1. Comparing the two, we find that the -\log p(y|x) in Cross-Entropy imposes a much larger penalty on misclassified samples. Therefore, it tends to correct misclassified samples more aggressively, while the final classification result remains close to the direct optimization of the smooth approximation of accuracy.
From this, we can derive a new perspective on what makes an excellent loss function:
First, find a smooth approximation of the evaluation metric, preferably expressed as an expectation over each sample. Then, pull the error in the wrong direction toward infinity (to ensure the model focuses more on incorrect samples), while ensuring a first-order approximation to the original form in the correct direction.
Final Summary
This article mainly discussed the problem of how to optimize accuracy. It briefly introduced and reviewed the recent paper "EXACT: How to Train Your Accuracy" and then provided my own analysis on "why optimizing Cross-Entropy can yield better accuracy results."
Original address: https://kexue.fm/archives/9098
For more details on reprinting, please refer to: "Scientific Space FAQ"