As is well known, classification models typically obtain an encoding vector first, followed by a Dense layer to predict the probability of each category. During inference, the category with the highest probability is output. However, have you ever considered this possibility: a trained classification model might contain “unpredictable categories”? That is, regardless of the input, it is impossible to predict a certain category k; category k can never become the one with the maximum probability.
Of course, this situation generally only occurs in scenarios where the number of categories far exceeds the dimensionality of the encoding vector; conventional classification problems are rarely so extreme. However, we know that a language model is essentially a classification model, and its number of categories is the total size of the vocabulary, which often far exceeds the vector dimensionality. So, does our language model have “unpredictable words”? (Considering only Greedy decoding).
Does it Exist?
The ACL 2022 paper “Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice” first explored this issue. As the title suggests, the answer is: “it exists in theory but the probability of occurrence in practice is very small.”
First, let’s look at “theoretical existence.” To prove its existence, we only need to construct a specific example. Let the category vectors be \boldsymbol{w}_1, \boldsymbol{w}_2, \dots, \boldsymbol{w}_n \in \mathbb{R}^d and the bias terms be b_1, b_2, \dots, b_n. Assuming category k is predictable, there must exist a \boldsymbol{z} \in \mathbb{R}^d such that: \langle\boldsymbol{w}_k, \boldsymbol{z}\rangle + b_k > \langle\boldsymbol{w}_i, \boldsymbol{z}\rangle + b_i \quad (\forall i \neq k) Conversely, if category k is unpredictable, then for any \boldsymbol{z} \in \mathbb{R}^d, there must exist some i \neq k such that: \langle\boldsymbol{w}_k, \boldsymbol{z}\rangle + b_k \leq \langle\boldsymbol{w}_i, \boldsymbol{z}\rangle + b_i Since we only need to provide an example, for simplicity, let’s first consider the case without bias terms and set k=n. In this case, the condition is \langle \boldsymbol{w}_i - \boldsymbol{w}_n, \boldsymbol{z}\rangle \geq 0. That is to say, for any vector \boldsymbol{z}, one can always find a vector \boldsymbol{w}_i - \boldsymbol{w}_n such that the angle between them is less than or equal to 90 degrees. It is not difficult to imagine that when the number of vectors is greater than the spatial dimension and the vectors are uniformly distributed in space, this can occur. For example, any vector in a 2D plane must have an angle of less than or equal to 90 degrees with at least one of (0,1), (1,0), (0,-1), (-1,0). Thus, we can construct an example: \left\{\begin{aligned} &\boldsymbol{w}_5 = (1, 1) \quad (\boldsymbol{w}_5 \text{ can be chosen arbitrarily})\\ &\boldsymbol{w}_1 = (1, 1) + (0, 1) = (1, 2)\\ &\boldsymbol{w}_2 = (1, 1) + (1, 0) = (2, 1)\\ &\boldsymbol{w}_3 = (1, 1) + (0, -1) = (1, 0)\\ &\boldsymbol{w}_4 = (1, 1) + (-1, 0) = (0, 1)\\ \end{aligned}\right. In this example, category 5 is unpredictable. If you don’t believe it, you can try substituting some values for \boldsymbol{z}.
How to Determine?
Now that we have confirmed that “unpredictable categories” can exist, a natural question is: for a trained model, given \boldsymbol{w}_1, \boldsymbol{w}_2, \dots, \boldsymbol{w}_n \in \mathbb{R}^d and b_1, b_2, \dots, b_n, how do we determine if there are unpredictable categories?
According to the description in the previous section, from the perspective of solving inequalities, if category k is predictable, then the solution set of the following system of inequalities will be non-empty: \langle\boldsymbol{w}_k - \boldsymbol{w}_i, \boldsymbol{z}\rangle + (b_k - b_i) > 0 \quad (\forall i \neq k) Without loss of generality, we again set k=n and denote \Delta\boldsymbol{w}_i = \boldsymbol{w}_n - \boldsymbol{w}_i, \Delta b_i = b_n - b_i. Note that: \langle\Delta\boldsymbol{w}_i, \boldsymbol{z}\rangle + \Delta b_i > 0 \, (i = 1, 2, \dots, n-1) \quad \Leftrightarrow \quad \min_i \langle\Delta\boldsymbol{w}_i, \boldsymbol{z}\rangle + \Delta b_i > 0 Therefore, as long as we try to maximize \min\limits_i \langle\Delta\boldsymbol{w}_i, \boldsymbol{z}\rangle + \Delta b_i, if the final result is positive, then category n is predictable; otherwise, it is unpredictable. Readers who have previously read “Discussion on Multi-Task Learning (II): Doing Gradient Things” will find this problem “familiar.” Specifically, if there are no bias terms, it is almost identical to the process of finding “Pareto optimality” in multi-task learning.
The problem now becomes: \max_{\boldsymbol{z}} \min_i \langle\Delta\boldsymbol{w}_i, \boldsymbol{z}\rangle + \Delta b_i To prevent the solution from diverging to infinity, we can add a constraint \|\boldsymbol{z}\| \leq r: \max_{\|\boldsymbol{z}\| \leq r} \min_i \langle\Delta\boldsymbol{w}_i, \boldsymbol{z}\rangle + \Delta b_i where r is a constant. As long as r is large enough, it will be sufficiently consistent with the actual situation, because the output of a neural network is generally bounded. The subsequent process is almost the same as in “Discussion on Multi-Task Learning (II): Doing Gradient Things”. First, introduce: \mathbb{P}^{n-1} = \left\{(\alpha_1, \alpha_2, \dots, \alpha_{n-1}) \left| \alpha_1, \alpha_2, \dots, \alpha_{n-1} \geq 0, \sum_i \alpha_i = 1 \right.\right\} Then the problem becomes: \max_{\|\boldsymbol{z}\| \leq r} \min_{\alpha \in \mathbb{P}^{n-1}} \left\langle\sum_i \alpha_i \Delta\boldsymbol{w}_i, \boldsymbol{z}\right\rangle + \sum_i \alpha_i \Delta b_i According to von Neumann’s Minimax Theorem, we can swap the order of \max and \min: \min_{\alpha \in \mathbb{P}^{n-1}} \max_{\|\boldsymbol{z}\| \leq r} \left\langle\sum_i \alpha_i \Delta\boldsymbol{w}_i, \boldsymbol{z}\right\rangle + \sum_i \alpha_i \Delta b_i Obviously, the \max step is achieved when \|\boldsymbol{z}\| = r and \boldsymbol{z} is in the same direction as \sum_i \alpha_i \Delta\boldsymbol{w}_i. The result is: \min_{\alpha \in \mathbb{P}^{n-1}} r \left\|\sum_i \alpha_i \Delta\boldsymbol{w}_i\right\| + \sum_i \alpha_i \Delta b_i When r is large enough, the influence of the bias term becomes very small, so this is almost equivalent to the case without bias terms: \min_{\alpha \in \mathbb{P}^{n-1}} \left\|\sum_i \alpha_i \Delta\boldsymbol{w}_i\right\| The solution process for the final \min has already been discussed in “Discussion on Multi-Task Learning (II): Doing Gradient Things”, mainly using the Frank-Wolfe algorithm, and will not be repeated here.
(Note: The above identification process is provided by the author and is different from the method in the paper “Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice”.)
How about in Practice?
The previous discussions are theoretical. So, is the probability of “unpredictable words” appearing in actual language models high? The original paper tested some trained language models and generative models and found that the probability of occurrence is actually very small. For example, the verification results of the machine translation model in the table below:
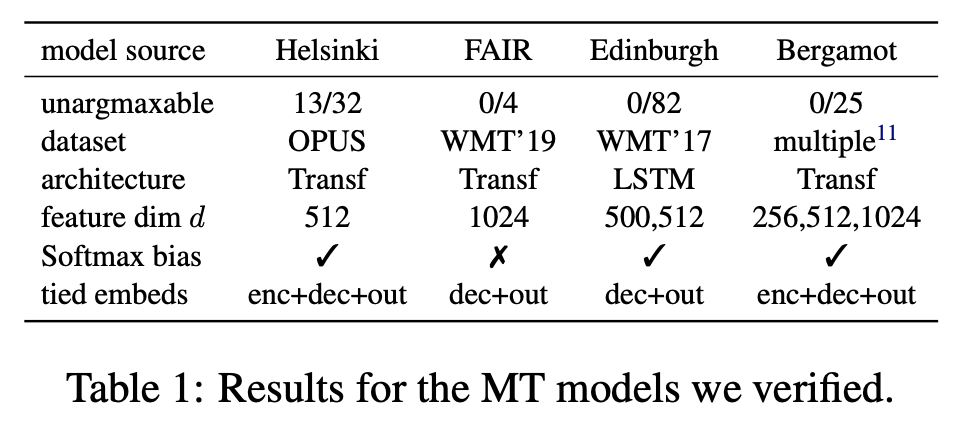
In fact, this is not difficult to understand. From the previous discussion, we know that “unpredictable words” generally only appear when the number of categories is much larger than the vector dimension, which is the “Low-Rank” mentioned in the original paper’s title. However, due to the “curse of dimensionality,” the concept of “much larger” is not quite what we intuitively think. For example, for a 2D space, a category count of 4 can be called “much larger,” but for a 200D space, even a category count of 40,000 is not necessarily “much larger.” The vector dimensions of common language models are basically several hundred, while the vocabulary is at most in the hundreds of thousands. Therefore, it is still not considered “much larger,” and thus the probability of “unpredictable words” appearing is very small.
In addition, we can also prove that if all \boldsymbol{w}_i are distinct but have the same magnitude, then “unpredictable words” will absolutely not appear. Therefore, this unpredictable situation only occurs when there is a large difference in the magnitudes of \boldsymbol{w}_i. In current mainstream deep models, due to the application of various Normalization techniques, situations where the magnitudes of \boldsymbol{w}_i differ greatly are rare, which further reduces the probability of “unpredictable words.”
Of course, as mentioned at the beginning of the article, the “unpredictable words” in this paper refer to maximization prediction, i.e., Greedy Search. If Beam Search or random sampling is used, then even if “unpredictable words” exist, they can still be generated. This “unpredictable word” is more of a fun but not very practical theoretical concept.
Final Summary
This article introduced a phenomenon that has little practical value but is quite interesting: your language model may have some “unpredictable words” that can never become the one with the highest probability.
Reprinting please include the original address: https://kexue.fm/archives/9046
For more detailed reprinting matters, please refer to: "Scientific Space FAQ"