I wonder if you have noticed a detail: current mainstream NLP pre-training is conducted on a fixed length (e.g., 512), and then the pre-trained model is directly applied to tasks with different lengths. It seems that no one has questioned this pattern, as if the model’s ability to automatically generalize to different lengths is a "matter of course."
Of course, I previously held no such doubts either, until a few days ago when I conducted experiments with the Base version of GAU. I discovered that GAU’s length generalization capability was not as good as imagined. After further analysis, I realized that this ability to generalize across lengths is not actually "taken for granted"...
Model Review
In "FLASH: Probably the Most Interesting Efficient Transformer Design Recently", we introduced the "Gated Attention Unit" (GAU), which is a new design merging GLU and Attention.
Beyond its effectiveness, GAU’s design impacts us in two main ways: first, it shows that single-head attention is not necessarily inferior to multi-head attention, establishing its status as "fast" and "efficient"; second, it shows that attention does not necessarily require Softmax normalization and can be replaced by a simple \text{relu}^2 divided by the sequence length: \boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right) This form leads to an interesting question: if we try to organize samples into the same length (e.g., 512) during pre-training, then n is almost always 512 during the pre-training phase. In other words, n acts as a constant. If we then use it for fine-tuning on other lengths (e.g., 64, 128), should this n automatically change to the sample length, or remain at 512?
Intuition suggests it should equal the sample length to be more adaptive, but the answer is counter-intuitive: fine-tuning with n fixed at 512 yields significantly better results than setting n to the actual sample length! This is thought-provoking...
Problem Localization
If we look solely at GAU’s pre-training performance, it outperforms standard Attention, so GAU’s fitting capability itself should be fine. It is just that the transferability of \frac{1}{n}\text{relu}^2(\cdot) regarding sample length is poor. To confirm this, I also tried pre-training GAU by mixing samples of different lengths and found that the results improved significantly.
So, what part of GAU could be the problem? It’s not hard to guess. The overall operation of GAU can be simplified as \boldsymbol{O}=(\boldsymbol{U}\odot\boldsymbol{A}\boldsymbol{V})\boldsymbol{W}_o, where \boldsymbol{U}, \boldsymbol{V}, \boldsymbol{W}_o are all token-wise, meaning they are not affected by changes in length at all. Therefore, the problem must reside in \boldsymbol{A}.
When we used standard Attention in the past, similar problems did not arise, to the point that we unconsciously felt this was a "natural" property. Thus, we need to find the problem by looking at the differences between GAU’s Attention and standard Attention. As mentioned earlier, there are two differences: one is the change from multi-head to single-head Attention, but this would at most cause some fluctuation in performance, whereas our results showed a sharp decline. Therefore, the problem can only lie in the other difference—the normalization method—specifically, the change from softmax to \frac{1}{n}\text{relu}^2(\cdot).
Verifying this hypothesis is simple. I replaced the normalization in GAU’s Attention back to Softmax and re-trained a GAU model. Upon fine-tuning and testing on tasks of different lengths, I found that the performance was significantly better than when using \frac{1}{n}\text{relu}^2(\cdot). Therefore, we conclude: Attention and Softmax are a better match.
Reasoning
Why does the more intuitive, length-adaptive n perform worse than a fixed n? Since we know Softmax doesn’t have this issue, let’s look for inspiration there. The Softmax operation is: a_{i,j} = \frac{1}{Z_i}\exp\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right),\quad Z_i = \sum_{j=1}^n \exp\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right) A direct question is: What is the relationship between Z_i and n? If Z_i = \mathcal{O}(n), then theoretically replacing Z_i with n should yield similar results, or at least not significantly worse ones.
However, we know the focus of attention is "attention"—it should have the ability to "focus" on a few tokens it deems important. Meanwhile, previous experimental results on efficient Transformers show that replacing standard Attention with Local Attention does not lead to a significant drop in results. Thus, we can expect that the Attention at position i basically focuses on a few tokens near i, and drops to nearly zero beyond a certain distance. In fact, many post-hoc visualizations show that trained Attention matrices are very sparse.
Synthesizing these results, we can conclude that there exists some constant k such that when |j-i| \geq k, \exp\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right) is very close to 0. Consequently, Z_i should be closer to \mathcal{O}(k) rather than \mathcal{O}(n). This implies that Z_i is likely independent of n, or at least its relationship with n is of a lower order than \mathcal{O}(n)! Therefore, if we want to replace Z_i with something else, it should be a function of a lower order than n^1, or even a constant.
Looking back at GAU, when its activation function is changed to \text{relu}^2(\cdot), the Attention situation is similar, perhaps even sparser. This is because the \text{relu} operation has a direct zeroing effect, unlike \exp(\cdot) which is always positive. Additionally, GAU "comes standard" with Rotary Positional Embedding (RoPE). In "Transformer Upgrade Path: 2. Rotary Positional Embedding", we derived that RoPE itself possesses a certain degree of long-range decay capability. Combining these conditions, GAU’s normalization factor should also be lower than \mathcal{O}(n) or even at a constant level.
Entropy Invariance
From this, we can summarize three solutions for GAU: first, use the same fixed n for both pre-training and fine-tuning; second, continue using dynamic sample length n, but pre-training must involve a mix of samples with different lengths rather than just a single length; third, add a normalization factor like Softmax and let the model learn it: a_{i,j} = \frac{1}{Z_i}\text{relu}^2\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right),\quad Z_i = \sum_{j=1}^n \text{relu}^2\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right)
Given these solutions, why do we still say "Attention and Softmax are a better match"? Where does GAU’s \text{relu}^2(\cdot) fall short? First, looking at the ablation studies in the original GAU paper, it shows that replacing \text{relu}^2(\cdot) with Softmax results in basically identical performance:
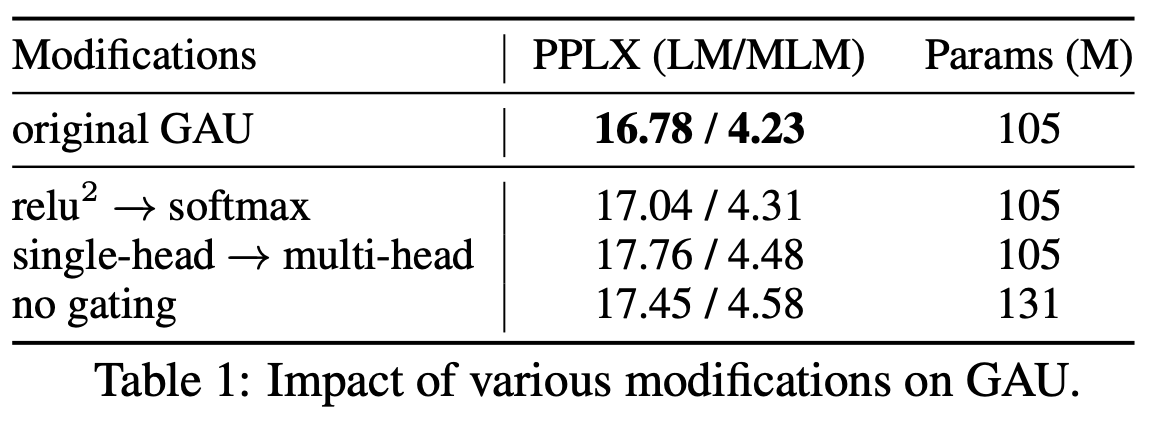
With this basic assurance, we can see why Softmax is better than \text{relu}^2(\cdot). Looking at the three GAU solutions mentioned, Solution 1 feels insufficiently adaptive, Solution 2 requires training with multiple lengths which feels less elegant, and Solution 3, after adding the normalization factor, becomes more "cumbersome" in form compared to Softmax. Therefore, overall, using Softmax appears more elegant and effective.
Furthermore, generalization capability can be simply divided into "interpolation" and "extrapolation." Here, interpolation (extrapolation) refers to the test length being shorter (longer) than the training length. When we said the normalization factor is of a constant magnitude, we were mostly speaking within the range of interpolation. For extrapolation, if the length is long enough, \boldsymbol{q}_i, \boldsymbol{k}_j are all "crowded" together, making it difficult to maintain the property where the value is near zero beyond a certain distance. If we use Softmax, we can derive an "entropy invariant" version to enhance the model’s extrapolation capability: \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{\log_{512} n}{\sqrt{d}}QK^{\top}\right)V In "Looking at Attention Scale Operations from Entropy Invariance", we conducted simple comparative experiments showing that this version indeed improves the model’s performance on lengths exceeding the training length.
So, can an "entropy invariant" version be derived for \text{relu}^2(\cdot)? The answer is no, because it essentially adjusts the entropy of the distribution through a temperature parameter. This requires the activation function not to possess positive homogeneity. For example, for a power function, (\lambda \boldsymbol{q}_i\cdot\boldsymbol{k}_j)^n = \lambda^n (\boldsymbol{q}_i\cdot\boldsymbol{k}_j)^n; after normalization, \lambda^n cancels out and has no effect. The activation function should ideally be of a higher order than a power function to achieve this regulation. The most common function higher than a power function is the exponential function, and exponential normalization is exactly Softmax.
Conclusion
This article analyzed the reasons for GAU’s poor fine-tuning performance and found that the normalization factor of Attention should be close to a constant magnitude. Therefore, GAU’s use of n or n^2 as a normalization factor leads to poor performance. Overall, I believe Attention is still a better match with Softmax; it is a solid baseline and can be further enhanced in extrapolation capability through "entropy invariance" extensions.
Original Address: https://kexue.fm/archives/9019
For more details on reprinting, please refer to: "Scientific Space FAQ"