About a year ago, we proposed Rotary Positional Embedding (RoPE) and released the corresponding pre-trained model RoFormer. Over time, RoFormer has fortunately received increasing attention and recognition. For instance, EleutherAI’s newly released GPT models with 6 billion and 20 billion parameters utilize RoPE positional encoding. Furthermore, Google’s newly proposed FLASH model paper explicitly points out that RoPE has a significant positive effect on Transformer performance.
At the same time, we have been striving to further strengthen the RoFormer model, attempting to take its performance to the "next level." After nearly half a year of effort, we believe we have achieved quite good results, which we are now officially releasing as "RoFormerV2":
Exploring the Limits
Since the rise of pre-trained models, many researchers have been interested in one question: where is the limit of pre-trained models? Of course, the word "limit" has many meanings. A series of works represented by GPT-3 attempts to explore the limits of parameter count and data volume, while Microsoft’s recently proposed DeepNet explores the limits of depth. For us, we want to know the performance limit under the same parameter count, attempting to "squeeze" the performance of pre-trained models to the fullest. RoFormerV2 is a product of this philosophy.
In simple terms, RoFormerV2 first appropriately simplifies the model structure based on RoFormer to achieve a certain speed increase. Regarding training, in addition to regular unsupervised MLM pre-training, we also collected over 20GB of labeled data for supervised multi-task pre-training. Under supervised training, the model’s performance improved significantly, basically achieving the optimal solution for both speed and effect under the same parameter count.
Notably, the RoFormer large with 300 million parameters surpassed several models with 1 billion+ parameters on the CLUE benchmark, ranking 5th. It is also the model with the fewest parameters among the top 5 on the leaderboard:
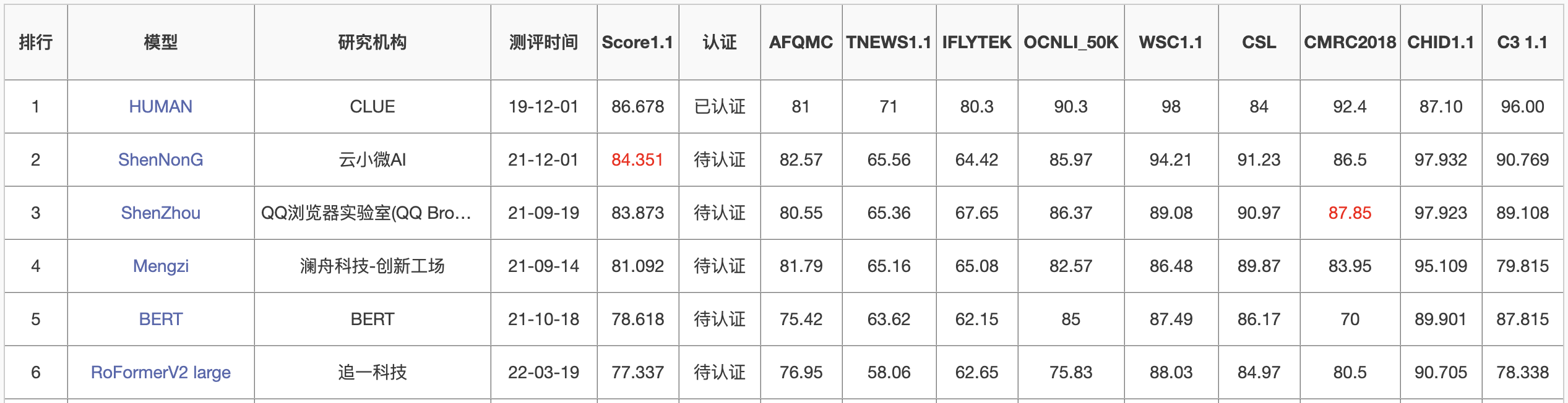
Model Introduction
Compared to RoFormer, the main changes in RoFormerV2 are the simplification of the model structure, the increase in training data, and the addition of supervised training. These changes allow RoFormerV2 to achieve a "win-win" in both speed and performance.
Structural Simplification
Structurally, RoFormerV2 primarily removes all Bias terms from the model, replaces Layer Norm with a simple RMS Norm, and removes the gamma parameter of the RMS Norm. These changes were mainly inspired by Google’s T5 model.
One might subconsciously feel that the calculation volume of Bias terms and the beta and gamma parameters of Layer Norm is very small, at least negligible for speed. However, the facts were beyond our expectations: after removing these seemingly "negligible" parameters, the training speed of RoFormerV2 improved significantly!
Some reference data are as follows (RoFormer and RoBERTa have similar speeds, so they are not listed separately; the base version was tested on a 3090 GPU, and the large version was tested on an A100 GPU):
| Seq Length | Training Speed | Seq Length | Training Speed | |
|---|---|---|---|---|
| RoBERTa base | 128 | 1.0x | 512 | 1.0x |
| RoFormerV2 base | 128 | 1.3x | 512 | 1.2x |
| RoBERTa large | 128 | 1.0x | 512 | 1.0x |
| RoFormerV2 large | 128 | 1.3x | 512 | 1.2x |
Unsupervised Training
Like RoFormer, RoFormerV2 is first pre-trained using the MLM task. The main differences are twofold:
RoFormer was trained on top of RoBERTa weights, while RoFormerV2 is trained from scratch;
RoFormer’s unsupervised training used only about 30GB of data, while RoFormerV2 used 280GB of data.
Training from scratch is more difficult than continuing training on existing weights, mainly reflected in the fact that the Post Norm structure is harder to converge. To this end, we proposed a new training technique: designing the residual as \boldsymbol{x}_{t+1} = \text{Norm}(\boldsymbol{x}_t + \alpha F(\boldsymbol{x}_t)) where \alpha is initialized to 0 and linearly increased slowly to 1. For related discussions, you can also refer to "A Brief Discussion on the Initialization, Parameterization, and Standardization of Transformers". This scheme is similar to ReZero, but the difference is that in ReZero, \alpha is a trainable parameter and the \text{Norm} operation is removed. Experiments show that our modification yields better final results than ReZero and was almost the optimal solution before DeepNet.
Multi-task Training
As mentioned earlier, the structure of RoFormerV2 was simplified to gain speed, but since there is "no free lunch," the performance of RoFormerV2 would slightly decrease compared to RoBERTa and RoFormer under the same training settings. To compensate for this decline and more effectively tap into the model’s potential, we added supervised multi-task pre-training.
Specifically, we collected 77 labeled datasets totaling 20GB and
constructed 92 tasks for multi-task training. These datasets cover
common natural language understanding tasks such as text classification,
text matching, reading comprehension, information extraction, and
coreference resolution, aiming to provide the model with comprehensive
natural language understanding capabilities. To complete the training,
we further developed a multi-task training framework based on
bert4keras, which flexibly supports mixed training of tasks
in different formats and integrates techniques such as gradient
normalization (refer to "Talk
on Multi-task Learning (II): Gradient Matters") to ensure each task
achieves the best possible result.
RoFormerV2 is not the first model to attempt multi-task pre-training. Before it, MT-DNN, T5, and the recent ZeroPrompt have all affirmed the value of multi-task pre-training. We mainly conducted thorough verification on Chinese and were the first to open-source it.
Experimental Results
We primarily compare the performance on the CLUE benchmark:
| iflytek | tnews | afqmc | cmnli | ocnli | wsc | csl | cmrc2018 | c3 | chid | cluener | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT base | 61.19 | 56.29 | 73.37 | 79.37 | 71.73 | 73.85 | 84.03 | 72.10 | 61.33 | 85.13 | 78.68 |
| RoBERTa base | 61.12 | 58.35 | 73.61 | 80.81 | 74.27 | 82.28 | 85.33 | 75.40 | 67.11 | 86.04 | 79.38 |
| RoBERTa large | 60.58 | 55.51 | 75.14 | 82.16 | 75.47 | 81.97 | 85.07 | 78.85 | 76.74 | 88.65 | 80.19 |
| RoFormer base | 61.08 | 56.74 | 73.82 | 80.97 | 73.10 | 80.57 | 84.93 | 73.50 | 66.29 | 86.30 | 79.69 |
| RoFormerV2 small | 60.46 | 51.46 | 72.39 | 76.93 | 67.70 | 69.11 | 83.00 | 71.80 | 64.49 | 77.35 | 78.20 |
| RoFormerV2 base | 62.50 | 58.74 | 75.63 | 80.62 | 74.23 | 82.71 | 84.17 | 77.00 | 75.57 | 85.95 | 79.87 |
| RoFormerV2 large | 62.65 | 58.06 | 76.95 | 81.20 | 75.83 | 88.03 | 84.97 | 80.50 | 78.34 | 87.68 | 80.17 |
As can be seen, the improvement from multi-task training is quite considerable. In most tasks, RoFormerV2 not only "recovered" the performance gap caused by structural simplification but also achieved certain improvements. On average, it can be considered to have reached the best performance among models of the same class. Additionally, on the CMNLI and CHID tasks, RoFormerV2 is not as good as RoBERTa. This is because both tasks have a very large amount of training data (in the hundreds of thousands). When the amount of training data is large enough, the model’s performance mainly depends on the model capacity, and the improvement brought by multi-task training is relatively small.
Therefore, in summary: if your task type is relatively conventional and the data volume is not particularly large, RoFormerV2 is often a good choice; if you want to speed up training a bit, you can also choose RoFormerV2; but if your task data volume is particularly large, RoFormerV2 usually will not have an advantage.
Summary
This article mainly provides a basic introduction to our newly released RoFormerV2 model. It primarily improves speed through structural simplification and enhances performance through the combination of unsupervised pre-training and supervised pre-training, thereby achieving a "win-win" in both speed and effect.
When reprinting, please include the original address of this article: https://kexue.fm/archives/8998
For more detailed reprinting matters, please refer to: "Scientific Space FAQ"